1. 前言
深度学习软件工程具有一体两面性:单卡的功能完备性、质量、用户体验以及多卡大规模。多卡大规模的出现是为了解决这样一个主要矛盾,即:“日益增长的数据、模型训练的需求与当前单卡计算能力无法满足这个需求之间的矛盾”,而分布式训练可以通过扩展卡子的规模解决这个矛盾,因此,这就是分布式训练的价值。
然而,正如懂得很多道理,仍旧过不好这一生一样,懂得很多分布式训练的理论与知识,也不一定就能做好一个分布式训练系统。把这么多机器连接跑起来、跟跑好也是两回事,分布式训练是一门实践的软件工程,只有你PK过设计方案,调试过一个个Bug,手把手的敲过一行行的代码,为了性能指标能达标无所不用其极的去验证各种性能优化方案,才能知道细节在哪里,难点在哪里,痛点、挑战点在哪里。因此,宏观处着眼,微观处着手,才能完全理解分布式训练的道理。
一个知识领域里的 “道 法 术 器” 这四个境界需要从 微观、中观以及宏观 三个角度来把握,微观是实践,中观讲方法论,宏观靠领悟。本系列文章我把它命名为《分布式训练与推理实战》,从工程实战的角度拆解分布式训练里最重要的十八个套路,也是从“微观实践、中观方法论、宏观领悟”这三个维度系统性的讲述分布式训练技术,本文讲述第1式,也是最难讲清楚的一式(也后续再迭代更新),即本质的一问:“什么是分布式训练“。
2. 什么是分布式训练
简单来说,分布式训练 = 分布式训练系统 = 分布式系统 + 训练系统,因此,要解答什么是分布式训练就需要解答什么是分布式系统以及什么是训练系统,而“系统 = 要素x连接 + 目的 + 边界”,因此进一步的就是需要分析分布式系统的要素、连接、目的与边界以及训练系统的要素、连接、目的与边界。
2.1 分布式系统
在AI训练过程中采用单卡总会遇到一些问题,比如原始的数据样本太大无法加载进训练卡,或者模型太大无法训练,那么这就需要用到分布式技术把大量的数据分割成小块由多个训练卡分别进行计算,在更新运算结果后,再将结果统一合并得出最终的可用模型。百科上对分布式系统的定义有:
1 | |
即:
分布式系统是指其组件位于不同的网络计算机上的系统,这些组件通过相互传递消息来进行通信和协调其动作,且彼此相互交互以完成一个共同的任务目标。
从这句话可以得出三个结论:
- 分布式系统的组件是位于不同的网络计算机上的;
- 分布式系统的组件通过传递消息进行通信与协调的;
- 分布式系统的组件是通过相互交互以完成一个共同的任务目标,同时是有边界的;
因此基于此定义,拆解分布式系统的概念,从中可以看到分布式系统里的要素即为组件,连接即网络,目的是共同的任务目标。其中的位于不同的网络计算机上的“组件”是分布式系统的要素,即各种计算单元,比如Ai训练卡,“网络”是分布式系统的连接,即神经网与数据网,“共同的任务目标”是分布式系统的目的,即训练,至此,再进一步抽象,可以推导出分布式系统的公理化定义,也是分布式系统的本质理论定义:
1 | |
在这个公式里,计算即计算单元,是各种AI训练卡,比如GPU, TPU, DPU, DTU。网络即网络连接单元,在单个训练卡内为计算用的神经网,主机内的多个卡子之间是PCIE 以及PCIE Switch,以及各种高带宽通信网,比如GenZ,CXL,NVLINK,OpenCAPI,CCIX等,在主机之间是各种通信网络,比如RDMA网络、InfiniBand网络、普通的TCP网络以及对应的各种交换机,另外从磁盘 + 主机内存 + 训练卡的HBM这个IO路径我们认为属于IO网络,而这里的目的 即训练,同时这个系统是有边界的,其专注于解决Ai训练过程中的难题,不是什么功能都能往里塞都能解决。
2.2 训练系统
以数据并行随机梯度下降( SGD )技术为例,神经网络训练的过程如下:
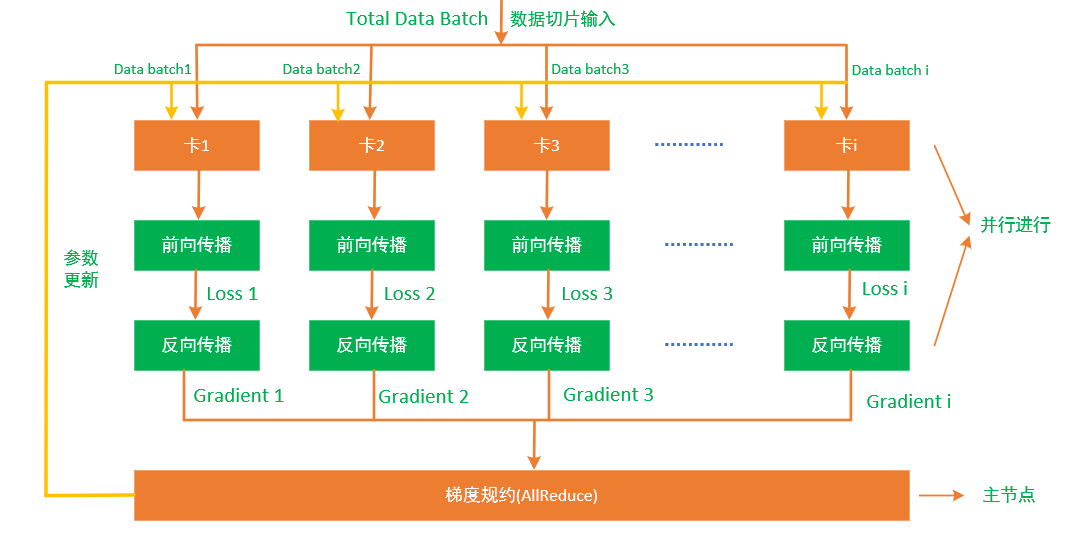
1,首先需要通过在第一个step进行Broadcast操作将参数同步到集群内的所有的训练卡上;
2,将数据样本切片分发到整个集群的每张训练卡上并且通过data pipeline技术将数据样本加载进训练卡的高速内存空间内,作为输入X;
3,每个训练卡在其数据样本上运行前向传播,计算出误差LOSSi;
4,对计算出的LOSSi进行反向传播,得到梯度GRADi;
5,所有的训练卡在主机内及主机之间进行集合通信并进行梯度归约(AllReduce);
6,最后再进行参数更新以获得新的梯度参数。
本质上分布式训练是数据加载、前向传播、反向传播、集合通信以及参数更新\这5个步骤的逻辑组合,因此,基于以上步骤,这里可以推导出训练系统的公式定义如下:
1 | |
从上面的步骤可知分布式训练是在固定的步骤迭代中进行的,并且需要系统内的所有的训练卡都完成它们的迭代步骤,才能进行最后的参数更新,这相当于在单个训练卡上执行梯度下降技术,但是通过在系统内所有的训练卡之间分发数据样本并同时执行计算来获得训练的加速。
2.3 举例说明
以TensorFlow为例说明模型的训练过程,TensorFlow 是用数据流图做计算的,如下图所示:
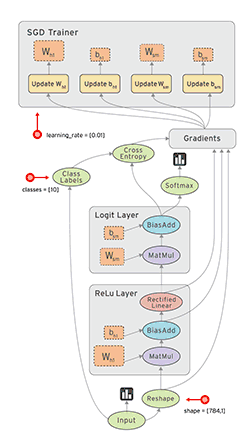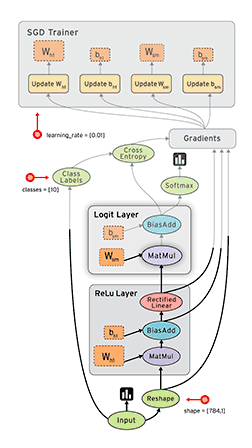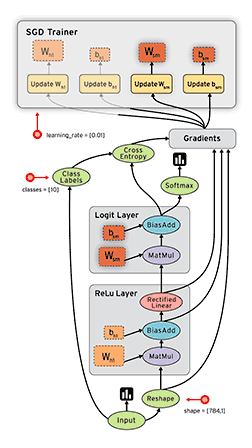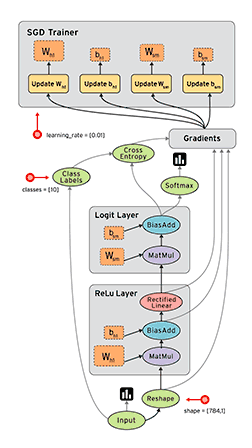
图中显示了 TensorFlow 的训练过程,其包含输入(input)、塑形(reshape)、Relu 层(Relu layer)、Logit 层(Logit layer)、Softmax、交叉熵(cross entropy)、梯度(gradient)、SGD 训练(SGD Trainer)等部分。
它的训练过程是,首先从数据分片输入开始,经过Reshape数据清洗后,进行前向传播运算,通过Relu 层后得到LOSS值,然后进入 Logit 层,再进行反向传播并且用 Cross Entropy、softmax等 来计算梯度,接着进行梯度归约(Allreduce),这一步在分布式场景就涉及集合通信的过程,最后进行参数更新SGD Trainer,如此迭代循环直到获得收敛指标达标的结果为止。
4. 小结
采用分布式训练的目的往往也是因为数据量或模型太大,一个训练卡放不下,因此对数据或者模型进行切分,分发到多卡上进行计算与归约。本文很概况性的讲述了什么是分布式训练,简单来说分布式训练就是分布式计算的一种,通过对数据样本的计算,得出最后可用的模型再用于数据推理。本系列文章的后续内将展开讲述分布式训练系统的基础理论、训练过程、质量保证、集合通信、系统工程、产品化等,同样分布式训练系统除了解决训练所带来的各种故障也还需要解决分布式所带来的各种故障。
日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
5. 作者简介
常平,中科大硕,某AI芯片公司深度学习高级软件主管、架构师,前EMC资深首席工程师,主要工作背景在深度学习、Ai平台、系统调优、大数据、云计算以及Linux内核领域。
6. 参考资料
[1] https://blog.tensorflow.org/2019/09/tensorflow-20-is-now-available.html
7. 版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。