1. 前言
不同于教科书里讲的深度学习的评价指标,这里主要讲述生产训练中常用的评价指标。通常在分布式训练中对训练的过程与结果会进行评价,比如选择一个评价指标:准确率,即表明模型求解给定问题的准确度。而本文提到的评价指标主要分为两大类,即训练结果评价与训练系统评价。
2. 训练指标
教科书里经常提到的深度学习的评价指标有准确率、精确率、召回率、F1值等,如下:
准确率(Accuracy),所有的预测正确(正类负类)的占总的比重;
精确率(Precision),查准率,即正确预测为正的占全部预测为正的比例;
召回率(Recall),查全率,即正确预测为正的占全部实际为正的比例;
F1值(H-mean值),F1值为算数平均数除以几何平均数,且越大越好;
实际上这些指标在真正的生产过程中用的不多,在实际的分布式训练过程中,比较关心的训练评价指标有:
- 加速比(speedup),即多卡训练下的单卡吞吐量平均指标除以单卡训练下的吞吐量平均指标,比如,大规模训练下的 ResNet-50 v1.5的单卡FPS指标是600,而单卡训练的FPS指标是800,那么加速比即 600/800 = 0.75,加速比体现的是训练集群的效率与可扩展性,越高的加速比表明训练集群的资源利用率越高,但是越高的加速比要求对训练集群的技术要求也越高。比如 一个 1000张卡的训练集群,要求 加速比 0.9以上,那么对于主机间的网络、主机内的网络、全栈软件、训练卡内部的硬件架构、集合通信拓扑算法、训练算法的优化等的要求都极高,这就涉及到整个分布式训练系统的问题,而不是单个点能彻底解决的;
- 吞吐量,sequence/sec 或 FPS, 即每秒能处理的图片数或数据量;
- 收敛时间(Time)与训练次数(epoch),生产过程中对训练所有的时间是有要求的,假设给定一个模型的训练次数(epoch)为100,如果要把这个100次都训练完需要 好几天,甚至好几个星期,那么可以认为生产不适用,基本上可以定义 训练一个模型到收敛需要 24小时以上,都可以看做是生产不适用,需要扩大训练集群的规模,使之训练时间控制在24小时之内;
- 平均准确率(eval Accuracy),平均准确率是训练是否收敛的重要评判标准之一,比如定义一个 Resnet50 v1.5 的训练模型的准确率为 76%,如果训练结束的平均准确率能达到这个值就认为训练是收敛的;
- 可收敛,训练的最终结果可以达到 平均准确率的要求,即认为可收敛,否者即任务训练失败;
- 学习率(Learning rate)与损失率(Loss),学习率大模型训练学习速度快,但是易导致损失率爆炸, 学习率小模型训练学习速度慢,而且容易过拟合,收敛速度慢;
- 曲线拟合(Curve Fitting),这是一个非常重要的评价手段,在XPU训练的场景下,通常先用一个已有的之前训练好模型为基础或先用GPU训练出一个基础模型,然后把XPU训练的结果指标跟GPU训练模型的指标进行比较,曲线拟合即认为XPU的训练结果达标,这也是调试XPU训练结果的一个重要手段。这里埋一个问题,按照曲线拟合的说法,假设有一个2000张XPU卡的集群,怎样评价这个集群训练的结果是正确的?以GPU训练的结果做比较,那么找一个这么大规模的GPU集群进行训练然后得到想要的模型做基础匹配也是不大现实的,那么需要采用什么技术方案才能解决这个问题?
以TensorBoard为例,说明模型的评价指标,在下面的命令行列输入一个baseline:/log_path_2:
1 | |
这个baseline 的模型已经确定是精度达标,生产可用的。然后 XPU训练的模型的 training_model:/log_path_1 与这个GPU训练处的baseline进行比,在tensorboard里可以表现如下图:
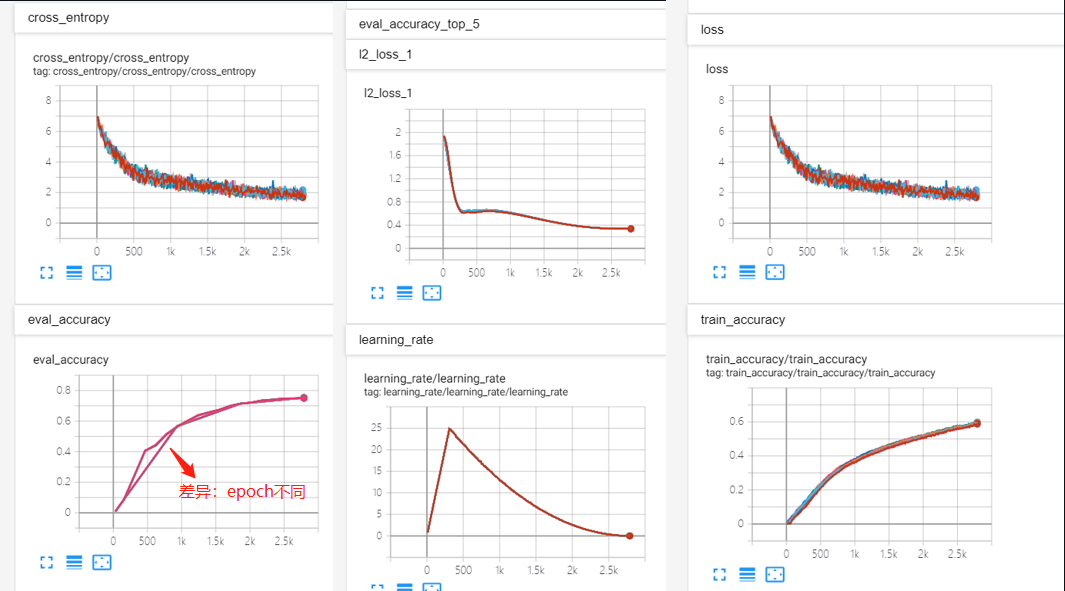
在上图里,新的模型的eval_accuracy值与baseline的值最终是一样的,这说明训练结果是收敛且精度达标,eval_accuracy中间的线有点差异是由于按不同的训练次数进行tensorboard指标保存所造成。新模型的Loss线与Learning_rate 线也与基础线吻合,这说明XPU训练的模型质量可生产适用。eval_accuracy、Loss、Learning_rate是三个最重要的度量指标,只要这样三个指标达标,那么大概率即可判断这个在XPU下新训练的模型具备生产可用能力。
3. 系统指标
分布式训练系统其本身也是一个分布式系统,因此除了训练领域相关的度量指标,也有与分布式系统质量有关的一套度量指标,其中比较重要的几项内容如下:
可用性(Availability),可用性指的是分布式训练系统长时间可对外提供服务的能力,通常采用小数点后的9的个数作为度量指标,按照这种约定“五个九”等于0.99999(或99.999%)的可用性,默认企业级达标的可用性为6个9。但是当前从时间维度来度量可用性已经没有太大的意义,因为设计得好的系统可以在系统出现故障得情况下也能保证对外提供得服务不中断,因此,当前更合适得可用性度量指标 是请求失败率;
可靠性(Reliability),可靠性一般指系统在一定时间内、在一定条件下可以无故障地执行指定功能的能力或可能性, 也是采用小数点后的9的个数作为度量指标,通常5个9的可靠性就可以满足企业级达标;
可伸缩性(Scalability),是指通过向系统添加资源来处理越来越多的工作并且维持高质量服务的能力,其受可用性以及可靠性的制约,集群规模越大出故障的概率越高从而降低可用性、可靠性,为了保证可用性以及可靠性达标,需要适配合理的可伸缩性指标;
韧性(resilience),通常也叫容错性(fault-tolerant),也就是健壮和强壮的意思,指的是系统的对故障与异常的处理能力,比如在软件故障、硬件故障、认为故障这样的场景下,系统还能保持正常工作的能力,分布式训练系统的容错能力是一个非常重要的指标。
4. 小结
本文从实践的角度讲述了分布式训练的训练结果评价指标与系统评价指标,这些指标是度量一个分布式训练系统与训练的模型是否生产可用的重要参考。日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
5. 作者简介
常平,中科大硕,某AI芯片公司深度学习高级软件主管、架构师,前EMC资深首席工程师,主要工作背景在深度学习、Ai平台、系统调优、大数据、云计算以及Linux内核领域。
6. 参考资料
7. 版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。