1. 概述
分布式训练服务框架与集合通信库的组合构成了分布式训练的整体服务软件栈,在第3篇、第4篇文章里已经剖析完集合通信的相关内容,而本文会以Horovod为例介绍数据并行下分布式训练服务框架的基本原理以及进行架构解析。当前,在分布式训练里分布式训练服务框架需要解决以下几个核心问题 :
- 计算与通信同步耦合问题:如果反向传播一产生一份梯度,就马上对其调用全局AllReduce,计算与通信同步耦合,容易造成死锁同时性能也会很不如意;
- 计算时间与通信时间串行问题:神经网络是分层的,梯度计算的过程是数据加载,然后前向传播算出损失值,再反向传播算出梯度,而反向计算时梯度是从输出层往输入层方向一层一层产生的,在有些模型里,如果需要等所有的梯度都计算完毕才能触发全局AllReduce,那么对性能的影响也会很大;
- 梯度生成的落后者问题:集群内每个计算节点的同一份梯度的产生不一定都是同一时刻的,如果梯度没有全部生成就发起对这个梯度的全局规约,否则容易造成训练出来的模型精度不达标或者不收敛的问题;
- 梯度融合问题:如果每一份梯度都触发一次全局AllReduce,在梯度Tensor较多的神经网络训练里,整体的训练系统性能会变得极低;
- 易用性问题:从TensorFlow,PyTorch迁移过来需要改的代码需要极少,从单卡训练迁移到多卡训练需要改动的代码也需要极少;
- 可移植问题:支持多种多样的深度学习训练框架,比如 TensorFlow、PyTorch、MxNet等,也能支持多种多样的通信库,比如openMPI、NCCL、Gloo、CCL、RCCL等;
- 可靠性问题:在集群训练的过程中网络时不可靠的、计算卡是会出故障的、服务器是会出故障的、系统软件也是会出Bug的,这些因素造成了分布式训练过程中还存在可靠性问题,如何解决这个问题也是一个难题。
软件是由人实现的,解析一个软件系统最难的地方在于从庞杂的代码里倒推出背后实现它的人的设计意图,为了更好的理解Horovod,本文会基于以上这几个分布式训练的核心问题,以Horovod为例介绍分布式训练服务框架的基本原理以及进行架构解析。
2. 基础知识
2.1 单卡训练
神经网络的训练,本质上就是Y=F(x)的迭代,通过反复输入X、输出Y,使得神经网络的参数变化与输入输出间的复杂关系拟合。在神经网络训练的过程中,通过输入数据利用梯度下降的方法进行迭代从而优化神经网络参数,并最终输出神经网络模型。而神经网络可以看作一种运算模型,其由大量的神经元(节点)相互联接构成,其由输入层、隐藏层以及输出层组合而成(如下图左侧所示)。神经元(neuron)是神经网络的基本计算单元,也被称作节点(node),它可以接受来自其他神经元或外部数据的输入,然后计算出一个输出(如下图右上角所示)。
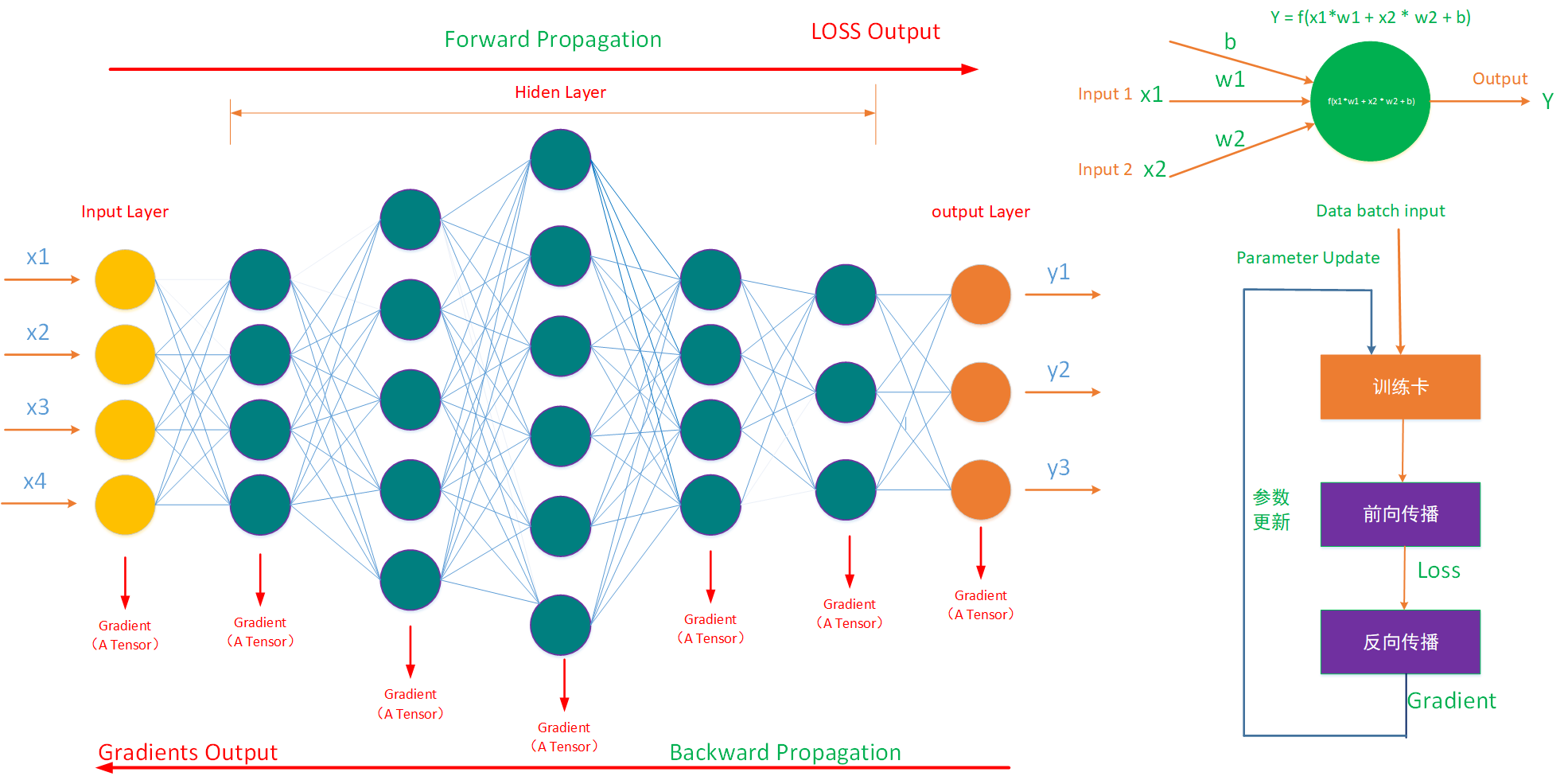
如上图右下角所示,在单卡训练迭代中,基于并行梯度下降法,会有以下操作:
第一步,读取部分数据,并且将数据加载进训练卡的存储空间;
第二步,对模型进行前向传播计算,从输入层往输出层一层一层的进行计算,得到损失差LOSS;
第三步,对模型进行反向传播计算,从输出层往输入层一层一层的进行计算,得到梯度值,注意这一步会把每一层都计算出一个梯度张量(Gradient Tensor)出来;
第四步,将新的到的梯度与部分数据 作为新的输入,重新开始以上步骤的迭代。
在这一步里有一个很重要的与性能优化相关的信息是反向传播是每一层输出一个梯度张量,以及反向传播是从输出层往输入层一层一层的进行计算的,这一点信息可以用通信隐藏性能优化与梯度融合优化。
2.2 多卡训练
以数据并行随机梯度下降法( SGD )为例,多卡神经网络的训练过程如下图,与单卡训练相比,多卡训练多了梯度全局规约的过程:
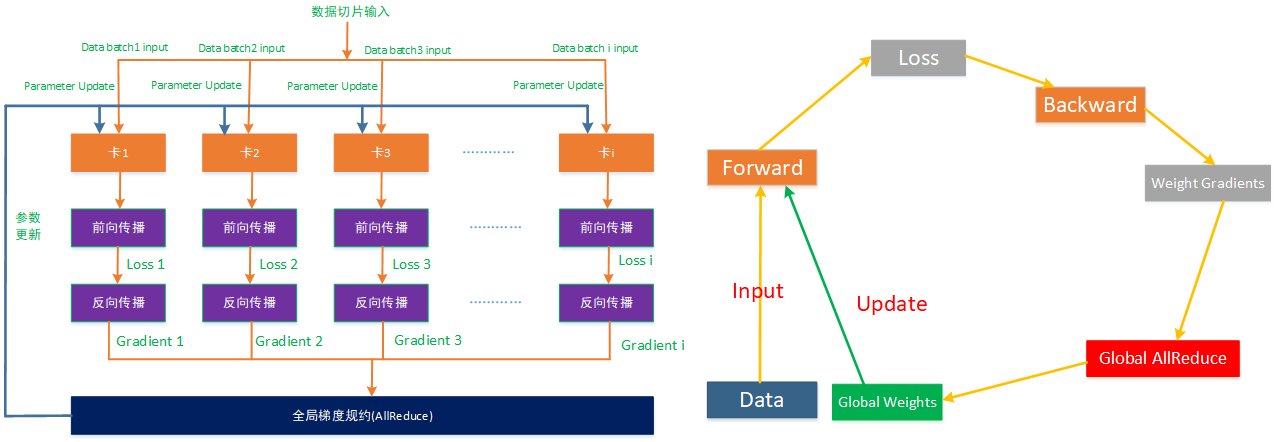
第一步,通过Broadcast操作将第一个节点参数同步到集群内的所有的训练卡上,保证每个计算节点的初始参数是一致的,同时训练脚本在多个计算节点上运行,每个计算节点包含了整体的模型参数;
第二步,将数据样本切片分发到整个集群内的个计算节点(训练卡)上并且通过数据流水技术将数据样本加载进训练卡的高速内存空间内,作为输入X;
第三步,每个训练卡在其数据样本上运行前向传播,计算出损失差LOSSi;
第四步,对计算出的LOSSi进行反向传播,得到梯度GRADi,这一步也需要注意得是每一层都会计算出一个梯度,同时梯度是以输出的Tensor来表示的;
第五步,所有的训练卡计算出来的部分梯度,在主机内及主机之间通过集合通信进行全局归约(AllReduce)得到全局梯度;
第六步,最后再将这个全局梯度作为参数进行更新,再进行以上2-5步骤的迭代从而获得新的梯度。
以上2-6步骤就是多卡并行梯度下降的基本思想,即多个计算节点通过分片的数据样本进行梯度计算,得到分区梯度后,再通过全局梯度规约以及将这个聚合好的梯度作为新的参数进行更新,从而实现并行梯度下降。
3. 几个核心问题
在本章节里会解读本文概述里提到的分布式服务框架需要解决的几个与性能、易用性等相关的几个核心问题,并且以Horovod为例讲述Horovod是如何解决这个几个难题的。
3.1 计算与通信解耦
在神经网络的训练过程中,每一神经网络层都会计算出一个梯度,同时梯度是以输出Tensor来表示的,如果反向传播一计算出一个梯度就马上调用通信去做梯度规约,将计算与通信同步耦合,那么整体的性能的表现就会很差。比如一个ResNet-50 v3的梯度张量个数是153个,如果一计算出一个梯度就马上进行通信,假设计算梯度花了1ms,通信这个梯度花了 500ms,那么这个过程就是 501ms,总体上就需要501x153 = 76653ms,即近76.6s才能完成一次梯度迭代。而将计算与通信解耦,计算的归计算,通信的归通信,通过性能优化策略减少通信的次数,既能提升整体训练性能也能避免某些死锁问题,比如计算梯度grad i的时候花了很长时间,而通信线程一直在等待这个梯度,表现出来就是死锁现象。
Horovod采用计算与通信分离的设计思想,解耦了计算过程与通信过程,从而提升了整体训练的性能与可靠性。如下图的Horovod逻辑架构图所示,从图中可以看出Horovod解耦了计算与通信,其将框架层计算出来的梯度request信息push 到一个消息队列message_queue里,同时将梯度信息push到一个Tensor_table里,再通过控制层在后台起一个loop线程,周期性的从消息队列里读取梯度消息,在控制层集群的节点之间协商达成一致后,再进行消息分发触发训练行为。
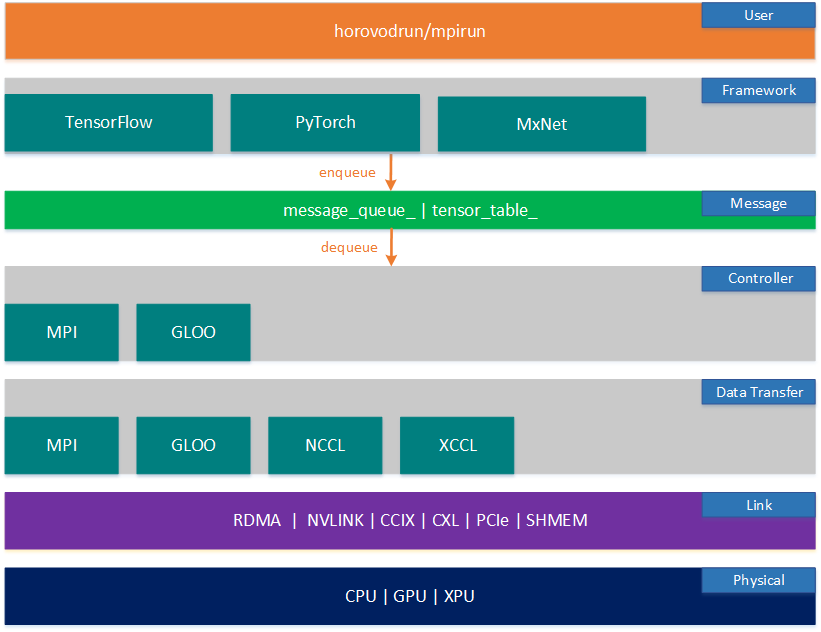
如上图可看出,Horovod从下到上分为7层:物理层、链路层、数据传输层、控制层、消息层、框架层以及用户层。框架层,控制层以及数据传输层体现了Horovod的核心设计理念,即:框架层,用户可以自定义Op,以插件的形式hack进框架;在控制层,worker节点与master节点之间协商达成触发训练行为的约定;在数据传输层,服务器内以及服务器之间采用集合通信库传输数据。
本质上Horovod的整体设计理念之一遵循的是生产者消费者模式,如下图所示:
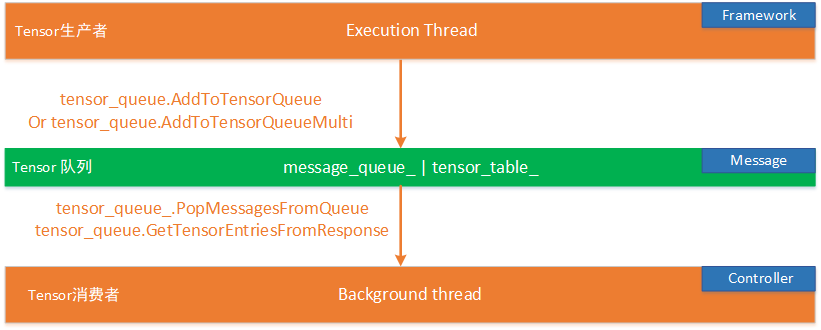
在Horovod里每个计算节点都会有有两个核心线程:Execution thread 和 Background thread :
- 生产者Execution Thread 是用来做梯度计算的,在TensorFlow、PyTorch之类的之类的训练框架计算出梯度Tensor后,将Tensor 信息push进tenor_table队列,同时将Tensor的request信息push进message_queue队列;
- 消费者Background thread 是做集合通讯以及全局Allreduce的,后台线程会每隔一段时间轮询消息队列,拿到一批Tensor信息之后,会进行相应的操作。
3.2 通信隐藏
神经网络是分层的,在训练的过程中,先是数据加载,然后前向传播算出LOSS,再反向传播算出梯度,而反向计算时梯度是从输出层往输入层方向一层一层产生的,如果需要等所有的梯度都计算完毕才能触发全局AllReduce,对性能不是很友好。如下图所示,计算时间与通信时间是串行的,如果能将全局梯度规约的通信时间与计算时间想办法并行起来,将通信时间隐藏在计算时间之内,那么就能节约梯度的训练时间从而提升分布式训练系统整体的训练性能。
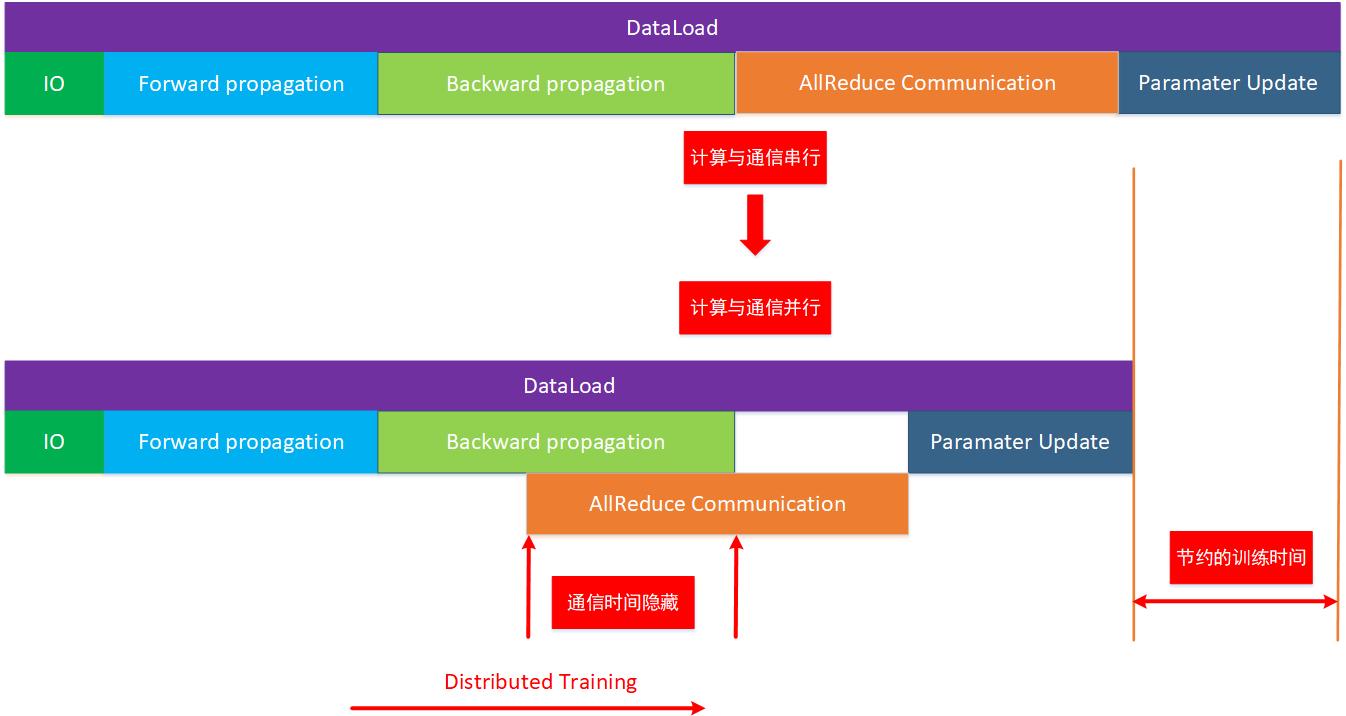
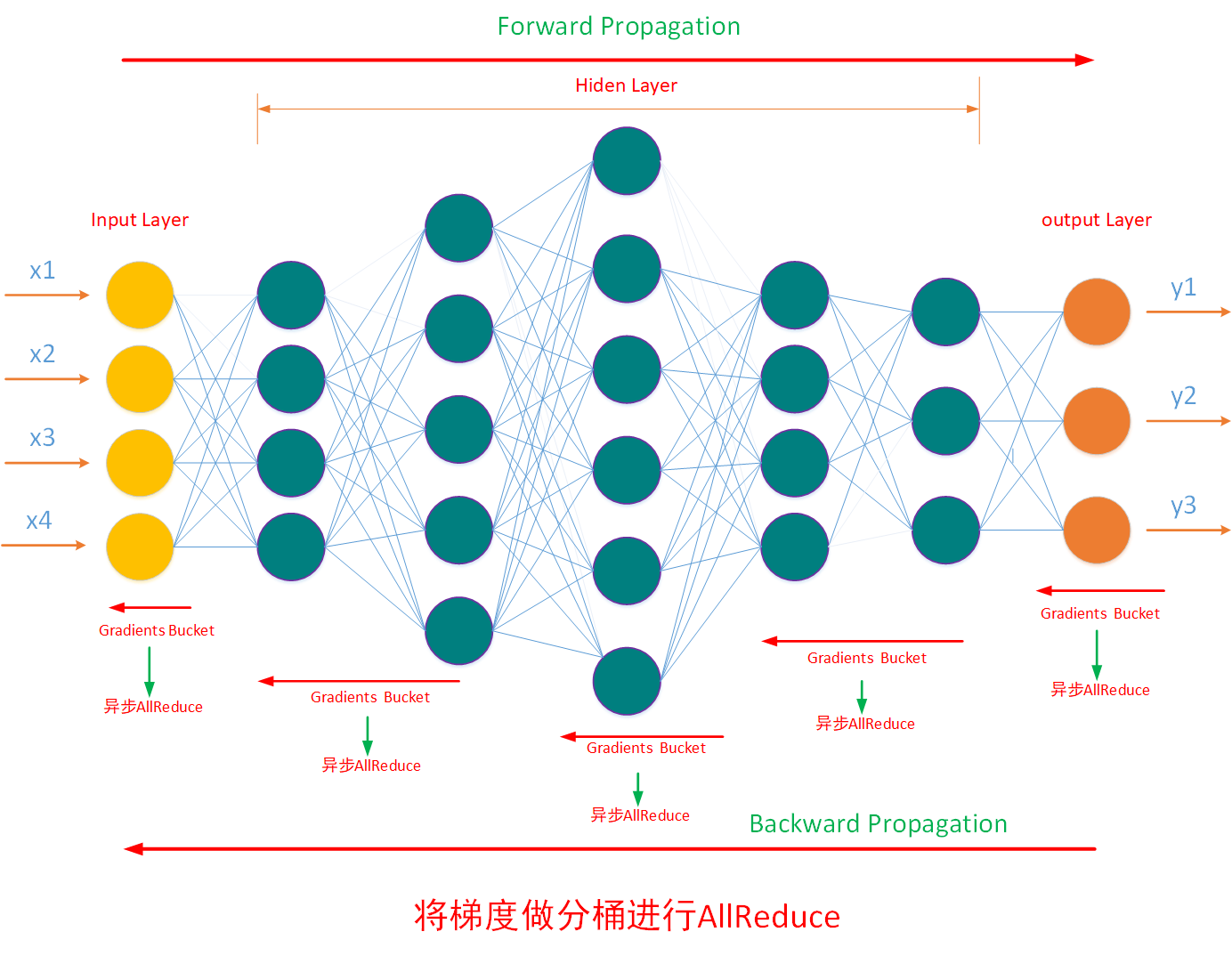
如下图所示,将计算出来的梯度进行分桶触发异步Allreduce,一边反向传播计算梯度,一边做部分梯度的全局规约通信,从而达到将通信时间隐藏在计算时间内的效果。而Horovod为达成这一效果,Background thread 会每隔一段时间轮询梯度消息队列里的梯度信息,获取了可以过全局规约的梯度后,就进行全局规约操作,而这个时间其他的梯度还在计算过程中,通过调整轮询的时间间隔从而达到调整梯度分桶的效果。
3.3 梯度协商
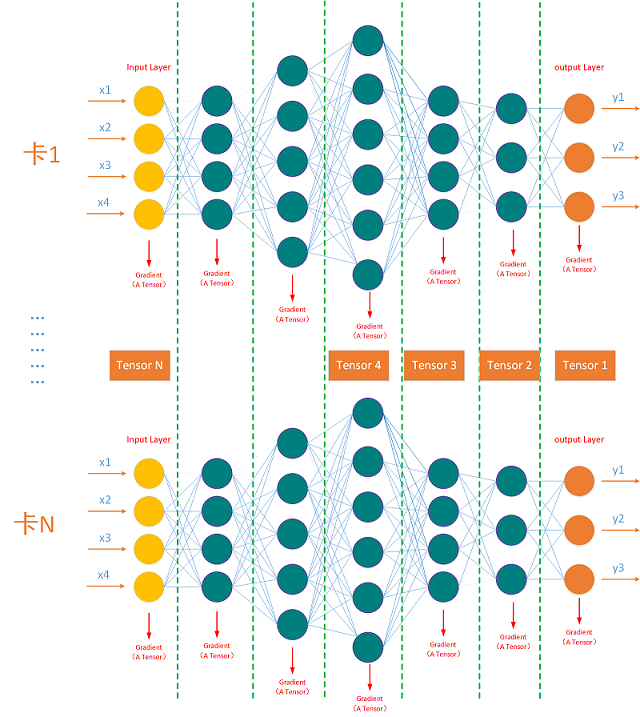
神经网络的每一层对应一个梯度Tensor,在分布式训练集群里每张训练卡对同一份梯度计算产生的时间是有差异的,当集群内每个计算节点的同一神经网络层的同一梯度都产生时,才能发起对这个梯度的全局AllReduce规约,否则容易造成丢梯度,训练出来模型精度不达标或者模型不收敛。比如在一个128卡的训练集群里,同一份梯度是对应同一个神经网络模型里的同一层神经网络的,只有每张训练卡上都计算出了同一层神经网络的梯度 才能对这一层神经网络的梯度进行全局规约,如下图所示:
Horovod设计了一种梯度状态协商机制,它将 计算节点Rank0 作为coordinator(master),其余的rank1-N节点进程为worker,由coordinator来协商确定同一份梯度是否在每个计算节点上都已经计算出来,只有在每个计算节点上都计算出来的同一梯度才可以进行全局规约操作。在Horovod里每个计算节点上都有一个message_queue以及tensor_table,而在coordinator节点上除此之外,还有一个message_table用于保存可以进行全局Allreduce的梯度请求次数信息。Horovod 控制面的ComputeResponseList 函数里实现了这一梯度的协商过程,在从message_queue获取了本节点生成的梯度信息后,coordinator会与其他节点协商这个梯度是否都计算出来,这一过程是阻塞进行的,这个协商过程如下图:
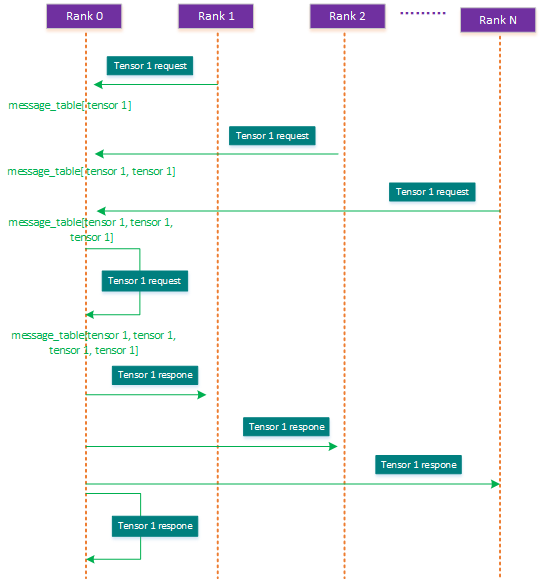
一个梯度是否能满足全局规约AllReduce的协商过程如下:
首先,集群内的每个计算节点进程都会往coordinator Rank0发送一个 tensor的请求request,表示说本节点这一层神经网络的梯度已经生成,比如tensor1,每个rank都会往rank0 发送一个本梯度tensor1已经计算出来的请求信息;
第二步,coordinator接收到节点的梯度协商请求后(包括本节点),会把收到的tensor请求次数进行累加,并将这个信息记录在message_table里,当这个梯度的请求信息达到集群内节点的个数时,比如在N个节点的集群,一个神经网络层的梯度tensor的通信请求出现了N次,那就表示在本集群里所有的计算节点都已经发出了对该梯度tensor的通信request,这就表明这个梯度tensor是符合全局规约要求的,就能进行集合通信全局规约,不符合要求的梯度tensor将继续留在message_table中,直到条件符合为止;
第三步,再接着coordinator会将满足全局allreduce规约条件的梯度Tensor通过response返回给其他节点,告诉其他节点这个梯度可以启动全局规约AllReduce。
经过这几步的协商达成梯度全局状态一致的目的,从而避免梯度丢失造成的模型精度不达标、不收敛或者进程死锁问题。
3.4 梯度融合
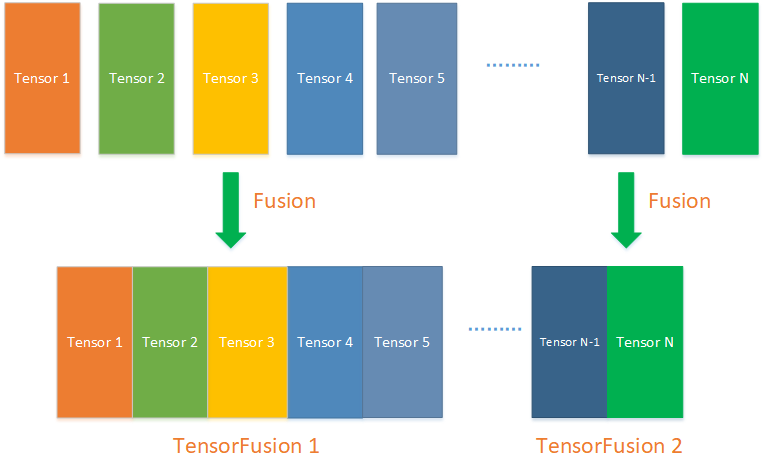
神经网络的每一层都能对应一个梯度,假设每生成一个梯度就进行一次全局规约时,100个梯度就需要进行100次全局通信100次全局规约,而通信对训练的性能有巨大的影响,这种情况表现出来的效果就是分布式训练集群的整体性能极差。通过梯度融合计算将多个梯度合成一个,从而减少全局规约的次数能大幅提高分布式训练的训练性能,如下图所示,将N个小梯度Tensor合成两个,能将全局通信的次数减少到2次,从而大幅提升训练性能,在Horovod里这个功能对TensorFusion特性。但这个特性也会与3.2通信隐藏特性相冲突,需要根据具体情况进行合理的调试优化。
3.5 易用性
从TensorFlow,PyTorch等框架迁移到Horovod需要改的的代码极少,horovod接入方式比较简单,与原生训练框架对比,主要的区别在于:
1 | |
3.6 可移植
可移植问题,Horovod通过 OP和OpKernels的插件化机制支持多种多样的深度学习训练框架,比如 TensorFlow、PyTorch、MxNet等。基于的opKernels的可定制化机制,Horovod自定义了Op然后hack了数据链路层的通信协议,从而达到在多个深度学习框架之间可移植。
3.7 可靠性问题
在集群训练的过程中网络时不可靠的、计算卡是会出故障的、服务器是会出故障的的,这些因素造成了分布式训练过程中需要考虑训练集群的可靠性,Horovod结合集合通信库Gloo对外提供了弹性训练的特性,但可靠性不只是弹性训练就能完全解决的,它还有更多的系统级的问题需要解决,因此可靠性问题留着一个后续研究问题,不在本文阐述。
4. 优点缺点、改进点
选择一个框架也是辩证的,在获得它优点的同时也得接受它的缺点,Horovod的优点、缺点以及改进点描述如下:
4.1 Horovod优点
- 简单易用、可移植,并且支持弹性训练提升了可靠性;
- 不依赖于某个框架,其通过MPI机制独立建立了一套分布式训练服务系统;
- 将计算与通信分离,完成了allreduce、allgather等集合通信工作,实现了规模可扩展;
- 巧妙的通过间隔轮询的机制支持通信时间隐藏,并且完成了梯度协商从而保证训练出来的模型是可收敛、精度达标的;
- 支持梯度融合,支持将小的tensor合并成一个大的tensor再进行通信传递,从而减小通信操作的额外开销;
- 自带压缩算法,可以减少集合通信的数据量;
4.2 Horovod的缺点
- 与GPU绑定,对新的训练加速设备的支持不够友好,缺乏设备插件化的机制,要添加一个新的训练加速设备比较困难;
- 所有的代码都与CUDA绑定,所有的性能优化机制都是针对GPU的,对新的DSA架构的芯片基本忽视;
- 弹性训练特性比较复杂,很难在生产上使用起来;
- 的Message_queue,Tensor_table缺乏容错机制,如果丢失数据容易造成丢tensor,从而影响整体模型的收敛与精度;
4.3 Horovod的改进点
- 简单易用的插件化支持新的训练芯片;
- 即支持SIMT架构芯片的性能优化,也支持DSA架构的芯片性能优化;
- 支持消息队列、张量表的容错,支持Rank 0 容错机制;
5. 思考题
- 问题1,将通信时间隐藏在计算时间内能有助于提升训练系统的整体性能,但这一特性是针对SIMT芯片的架构的进行性能优化的,如果DSA芯片不能支持这一特性,那应该如何优化Horovod从而大幅提升整体的训练性能?(可以确定这一定是能做到的)
- 问题2,梯度协商的过程中,每个梯度都需要协商一次,在梯度较多,网络规模较大的集群里,这一特性也会影响性能,如何进行优化才能有效提升Horovod性能?
- 问题3,不同的模型对梯度融合有不同的要求,那么梯度融合需要融合到什么程度才能有效提升性能?
可以说明的是,这三个问题解决后还能继续提升Horovod在DSA架构芯片上的整体的分布式训练系统级性能。
6. 小结
本文介绍了分布式训练的基础知识以及剖析了分布式训练服务框架所面临的几个核心问题,以Horovod为例从计算与通信解耦、通信隐藏、梯度协商、梯度融合、易用性以及可移植这几个角度倒推了分布式训练服务框架背后的设计意图,从而帮助大家能更好的理解分布式训练服务框架。
日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
7. 作者简介
常平,中科大硕,某AI芯片公司深度学习高级软件主管、架构师,前EMC资深首席工程师,主要工作背景在深度学习、Ai平台、系统调优、大数据、云计算以及Linux内核领域。
8. 参考资料
[1] https://www.changping.me
[2] https://horovod.ai
[3] https://www.cnblogs.com/rossiXYZ/p/14910959.html
[4] https://zhuanlan.zhihu.com/p/374575049
9. 版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。