前言
注:本思维模型系列文章已被infoq采纳并推荐至首页:https://www.infoq.cn/article/JjycubQz3YTBgozaZ4G9日拱一卒,功不唐捐,一个知识领域里的 “道 法 术 器” 这四个境界需要从 微观、中观以及宏观 三个角度来把握。微观是实践,中观讲套路,宏观靠领悟。本系列文章我把它命名为《分布式系统架构设计36式》,讲诉分布式系统里最重要的三十六个的中观套路,而微服务的本质也是分布式,因此搞明白这三十六个最重要的知识点也就同时能搞明白微服务。
“兵者,国之大事,死生之地,存亡之道,不可不察也”,这句话对企业来讲,兵即产品,国即企业,察即研究探讨,产品关系到企业的存亡,所以不可以不慎重地加以研究探讨。
我们知道一个产品的成功不只是技术的成功,它还包括商业、创新、管理、资本、运营以及销售等的成功。当打造一个产品的时候,通常来说工程人员往往会比较关注技术层面的东西: 方案、功能、难点、亮点以及如何实现等,深度有余但高度与广度往往不足 。一般有点经验的工程人员都可以从点或线的层面考虑一个产品的实现,但往往缺乏从面及体的层面看待一个产品的能力。
因此,如果说技术思维是架构师的一根DNA螺旋线,那么产品思维、创新思维以及商业思维等就是架构师的另外一根DNA螺旋线,只有两根DNA螺旋线俱全才能有机会进化出新物种。
动机
人的知识与能力可以从“时空”这两个角度进行评价,其可分为四个维度:深度、广度、高度以及跨度。空间角度指的是深度、广度、高度,时间角度指的是跨度。深度靠专研,广度靠学习,高度靠抽象,而跨度靠长久地积累经验。这四个维度组合成了一个人的知识与能力的时空度。
万事万物逃脱不出“不易、简易、变易”这三个层次,金庸先生的《天龙八部》里少林寺有72技,其每一技又千变万化,想要样样精通,今生无望,然而练就“小无相功”却可以以这功法催动不同的“技”,甚至可以比原版更具威力,以“不易 简易”之功施展“变易”之术。那么对于技术开发人员来说技术也是“变易”的,更新快,领域多,复杂度高,样样精通也是今生无望,那么需要的就是找出适合自己的“功”,技术思维模型、产品思维模型、创新思维模型、商业思维模型就是这样的“功”。
因此本系列文章提出了技术、产品、创新与商业这四个思维模型,这一系列文章不是为了解决具体的某个分布式系统设计里的难题,它提出了一种思维框架,从技术、产品、创新以及商业的角度,给工程人员以一种系统性的分析分布式系统设计难题的模型,这也是一种系统思维的体现。
商业思维模型
IBM有个商业战略思维模型叫做”五看三定“, 经过很多家企业的验证,表示效果很好。这里扩充”五看三定“思维模型为“五看三定六要素”思维模型,作为产品的商业模式思维模型。”五看三定六要素“即:五看:看趋势、看市场、看对手、看自己、看机会,三定:定目标、定策略、定执行,六要素:客户、产品、供给、盈利、创新及风险。
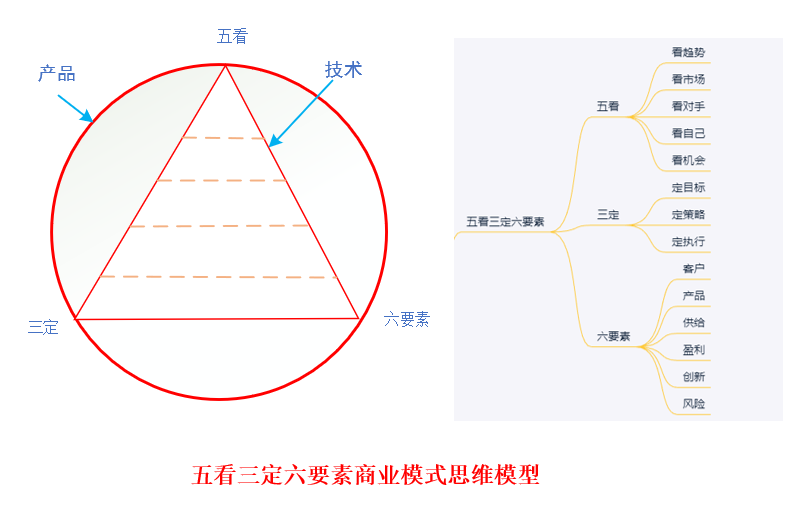
五看
1,五看,首先要看的是趋势,属于宏观的范畴,行业趋势、行业风向,国家政策,经济周期,技术趋势,资源方向等,从而判断出正确的资源投入方向;
2,接着看市场,看看市场需求在哪里?客户的真实需求在哪里?客户愿意买单的点在哪里?产品与市场的最佳适配点在哪里?从而输出正确的客户目标;
3,再看对手,可以从三个方面进行看对手:
赚得到钱,如果有对手已经验证过了这个市场可以获取高额利润,那么就可以确定这个方向的正确性;
赚不到钱,如果对手正在介入的市场领域属于赚不到钱的领域,那么自己去做赚不到钱的概率也一样非常的大,现在新介入的话就需要非常非常的谨慎;-
- 没有对手,如果是一个没有对手的领域,要么是新开拓的市场空白机会,要么根本就是没有真实的客户需求的伪需求市场,这也是需要非常谨慎介入方向。
4,看完对手就要看自己,看自己说的是,看看自己的优势在哪里,劣势在哪里,有什么关键资源能力,自己能做什么不能做什么,介入这个市场领域的话,对比其他对手有什么优势胜出,如果没有胜出优势就需要谨慎介入。
5,最后看机会,判断真机会的依据是:行业趋势正确,有真实的客户需求,对手有钱赚,自己团队有优势,那么这样的机会输出点就是”真机会“。
三定
五看后就要三定,看好机会后,需要定目标,定策略以及定执行。
1,首先定好需要达到的市场目标,比如3年利润1个小目标(1亿¥);
2,然后开始着手制定如何达到这个目标的策略,比如:1)分解这个目标,1年到什么阶段、2年到什么阶段、3年到什么阶段等;2)是先单点突破最佳盈利点,再以此为树干长出树枝?还是借助资源优势全面铺开?
3,再就是定执行,定策略是如何做的范畴,而定执行是让谁做,什么时候做出来的问题,属于生成资料、生成工具分配的范畴。
六要素
”五看三定“分析完后,更进一步需要进行商业模型六要素的分析[2]。
1,客户,客户指的是市场定位,是想赚谁的钱、不想赚谁的钱的问题,是客户是谁、又不是谁的问题,是客户如何取舍的问题。
2,产品,产品指的是打算用什么东西去赚钱,是卖产品还是卖服务,是提供的满客户需求的价值是什么又不是什么的问题。
3,供应,供应指的是如何生产出好产品以及怎么样把产品卖出去。如何打造与市场最佳适配的产品?如何保证技术与产品的最佳适配,如何交付出这样的好产品?然后又准备怎么把这样的产品卖出去?渠道在哪? 价格怎么定义?然后自己又有哪些强力的资源优势?这也是产品成败的一个非常关键的点。
4,盈利,盈利讲的是如何赚钱的问题,是做产品?还是做平台?或者做生态?然后又怎么保证可以持续地赚钱?做产品离钱近,一手交钱一手交货;做平台,投入大、但是空间也大;做生态,投入巨大、周期长,但是如果成了,那么收益也巨大。
5,创新,创新指的是以上四点如何创新,如何持续的创新,可以从寻找差异化入手,也可以从先同质化模仿再处处差异化创新入手,可以是 ”更好“,也可以是”不同“,还可以是”新生“。
6,风险,风险指的是风险管理,居安思危,失败风险是否在可承受的范围之内?以上五点的风险在哪里,方方面面是否都考虑周全?
依据以上近乎穷举的系统分析法,可以发现,为物联网以及IT运维市场专门设计一个存储系统是值得投入的一个机会点。
小结
本系列文章讲述了四个思维模型: “技术思维模型、创新思维模型、商业思维模型以及产品思维模型”,再结合分布式流存储做了简单的举例分析。本文讲述”商业思维模型“,日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这几个思维模型对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“[1],欢迎大家拍砖留念。
作者简介
常平,中科大硕,DELL EMC 资深首席工程师,主要从事分布式产品的交付、架构设计以及开发工作。
版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。
参考资料
[1]《第二曲线创新》 李善友
[2]《如何在一分钟内用5个问题讲清你的商业模式》 中欧商业评论,关苏哲
[3] Pravega.io