概述
通常,分布式存储系统以及分布式缓存系统习惯采用分布式哈希(DHT)算法来实现数据的分区分配(路由)以及负载均衡,普通的分布式hash算法通过增添虚拟节点,对物理的热点区间进行划分,将负载分配至其他节点,从而达到负载均衡的状态,但是这并不能保证集群的负载就一定很是的均衡。
而一种改进过的一致性Hash算法,即带边界因子的一致性Hash算法,其严格控制每个节点的负载从而能获得更好的负载均衡效果[1][2]。
普通的DHT算法
假设有8个Object,通过下图的DHT算法:
- object 0,1,2映射到了虚拟节点vNode0 : object 0,1,2 –> vNode0
- Object 3,4,5 映射到了vNode1:object 3,4,5 –> vNode1
- Object 6映射到 vNode2:object 6 –> vNode2
- Object 7映射到 vNodeN:object 7 –> vNodeN
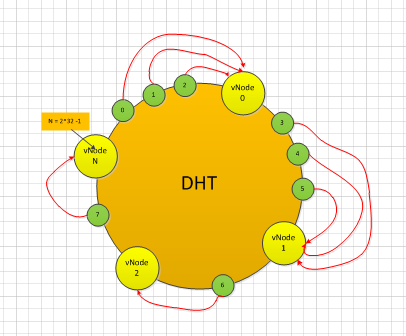
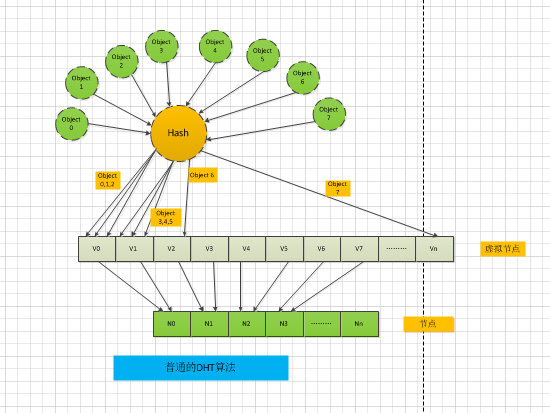
很明显,Vnode0和vNode1 都落了三个 object,而 vNode2和vNodeN 都只落了 1个Object,这里的DHT算法负债均衡因子并不是很好。
带负载边界因子的DHT算法
假设有8个Object,通过如下图的DHT with bounded loads算法:
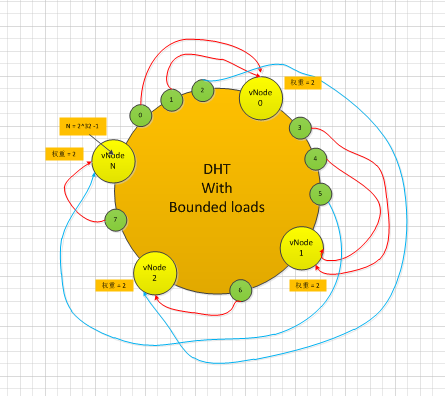
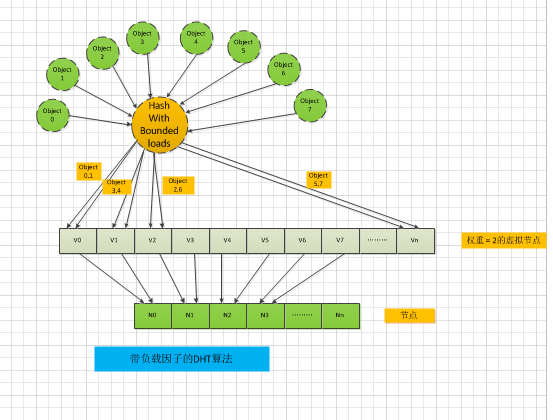
第一轮映射:
- object 0,1,2 需要映射到了虚拟节点vNode0,但是vNode0的权重因子是 2,因此只完成了 object 0,1 –> vNode0, object 2不能映射到节点 vNode0;
- Object 3,4,5 需要映射到了虚拟节点vNode1:但是vNode1的权重因子是 2,因此只完成了 object 3,4 –> vNode1, object 5不能映射到节点 vNode1;
- Object 6映射到 vNode2:object 6 –> vNode2
- Object 7映射到 vNodeN:object 7 –> vNodeN
第二轮映射:
- Object 2 映射到 vNode1,但是vNode1权重因子=0, 不能被接收,继续往下一个节点走,发现vNode2 权重因子是2,还剩权重因子1,可以被映射,因此 object 2–>vNode2
- Object 5 映射到 vNode2,但是vNode2现在的权重因子=0, 不能被接收,继续往下一个节点走,发现vNodeN 权重因子是2,还剩权重因子1,可以被映射,因此 object 5–>vNodeN
最终的映射结果是:
- object 0,1映射到了虚拟节点vNode0 : object 0,1 –> vNode0
- Object 3,4 映射到了vNode1:object 3,4 –> vNode1
- Object 2,6映射到 vNode2:object 2,6 –> vNode2
- Object 5,7映射到 vNodeN:object 5,7 –> vNodeN
很明显,Vnode0,vNode1,vNode2, vNodeN 每个节点都分到2个 object,
显然带负载边界因子的DHT算法负债均衡比普通的DHT算法来的好。
这些节点的负载因子可以从IO,CPU,MEM,Disk,Network等输入因子计算出来。
作者简介
常平,毕业于中国科学技术大学,获硕士研究生学历学位,10年+ 存储、布式系统、云计算以及大数据经验,曾就职于Marvell、AMD等,现就职于EMC,资深首席工程师,主要负责流式大数据处理平台的架构设计、编码及产品交付等。
参考资料
[1] https://research.googleblog.com/2017/04/consistent-hashing-with-bounded-loads.html