1. 概述
在深度学习的分布式训练里,Ring AllReduce拓扑算法奠定了数据并行训练的集合通信基础,但集合通信拓扑不只是仅有Ring Allreduce,经典的集合通信拓扑算法还有2D-Ring/Hierarchical Ring AllReduce,halving and doubling AllReduce,Butterfly AllReduce,2D-Torus AllReduce,2D-Mesh AllReduce,double binary tree等。拓扑算法很多,但也不是所有的拓扑算法都能满足实际的生产需求的,这需要具体问题具体分析、具体场景具体设计。
集合通信的难点在于需要在固定的网络互联结构的约束下进行高效的通信,集合通信拓扑算法与物理网络互联结构强相关,为了发挥网络通信的效率,也不是说就能随意发挥通信拓扑算法,更多的是在效率与成本、带宽与时延、客户要求与质量、创新与产品化等之间进行合理取舍。
充分发挥训练加速卡与网络的效率是通信拓扑算法的初衷,但除了设计高效的集合通信拓扑算法外,分布式训练中需要解决的通信难题还有:网络是异构的,网络带宽是有限的,主机内PCIE SWITCH是有亲和性的,网络是会出故障的,节点是有落后者效应的,设备成本是需要考虑的,数据中心是有部署约束的,用户是有多租户要求的等,这些属于产品化的范畴不在本文阐述。
2. 网络互联结构
分布式训练的集合通信拓扑算法与物理的网络互联结构强相关,而网络互联结构又多种多样,因此,本文需要先对网络互联结构进行约束,依据生产中常用的、既定的互联结构设计集合通信算法,网络互联结构描述如下:
2.1 服务内网络互联结构
以一台集成了8张训练加速卡的服务器为例,如下图:
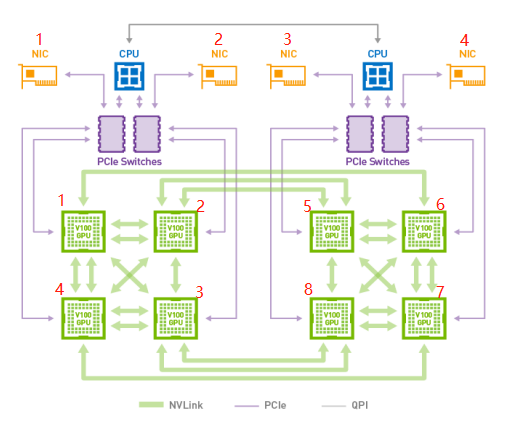
这台服务器内的网络互联情况如下:
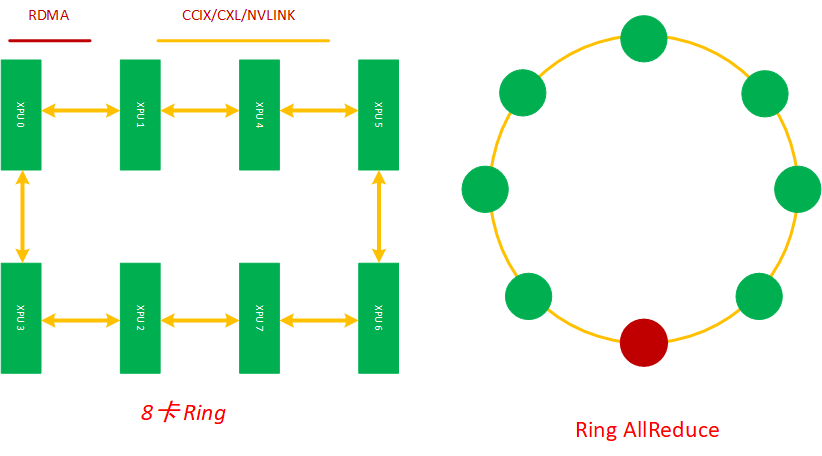
1)在这台服务器内,8张训练加速卡通过私有协议连接组成多个主机内的物理ring环,且可双工;
2)服务期内网络带宽 NVLINK>PCIE switch > QPI;
3)加速卡1、2、3、4之间两两全互联,加速卡5,、6、7、8之间两两全互联,2、5、3、8之间非全互联;
4)加速卡1、4与网卡NIC1 挂在同一个PCIE Switch上,具有亲和性,加速卡2、3与网卡NIC2挂在同一个PCIE Switch上,具有亲和性,而PCIE Switch之间也互联,因此 加速卡 1、2、3、4 与网卡NIC 1、NIC2具备亲和性,它们无需通过CPU的QPI线进行通信;
5)加速卡5、8与网卡NIC3 挂在同一个PCIE Switch上,具有亲和性,加速卡6、7与网卡NIC4挂在同一个PCIE Switch上,具有亲和性,而PCIE Switch之间也互联的,因此 加速卡 5、6、7、8 与网卡NIC 3、NIC4具备亲和性,它们也无需通过CPU的QPI线进行通信;
6)网卡可根据需要 选择 1张、2张、4张或8张,最多可以采用8张RDMA物理网卡;
2.2 服务器间网络互联结构
以一个训练加速卡集群为例,如下图是一个常用的CLOS互联架构方案:
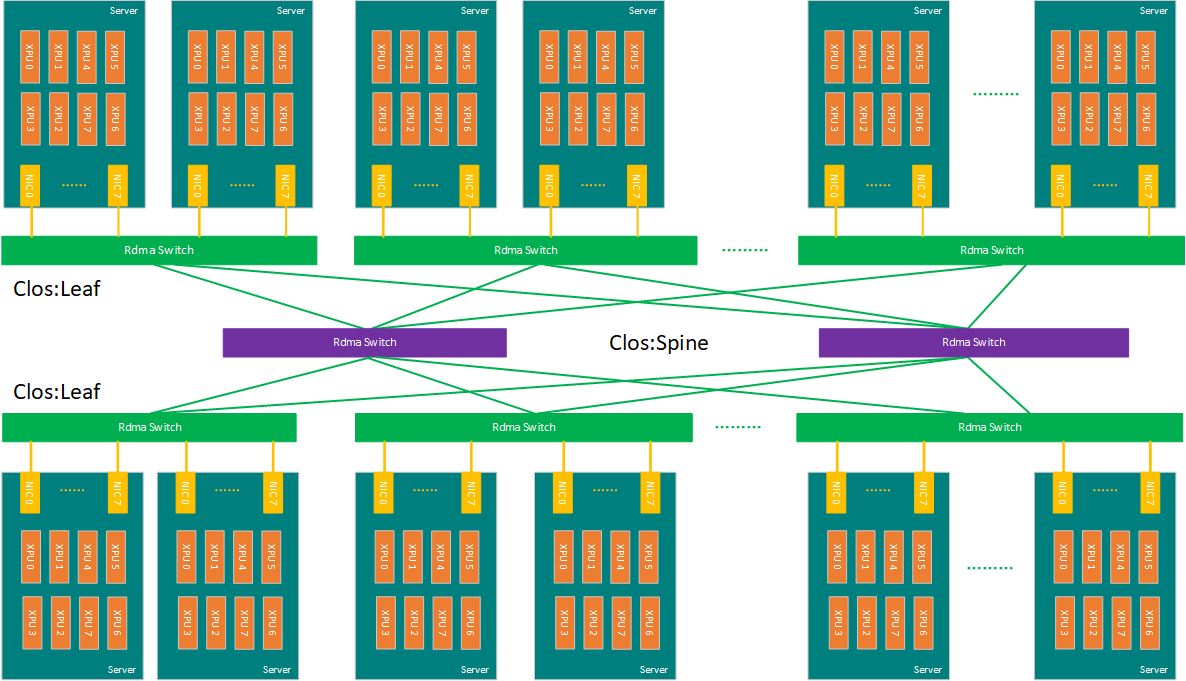
在这个集群内,其网络互联情况如下:
1)集群内每台服务器自带高速RDMA网卡,通过RDMA 交换机在主机间两两全互联;
2)交换机组成CLOS架构,分为Spine与Leaf交换机,当然也可以是更为高端的Spine、Leaf合一的高端交换机;
3)RDMA网卡与Leaf交换机互联,每台服务器的RDMA网卡数量根据成本与性能考虑,可以是1张、2张+每卡虚拟化4卡、4张+每卡虚拟化2卡或8张;
2.3 高速网卡及其虚拟化使用
RDMA网卡是双工的且可虚拟化,在这里每台服务器可根据成本、性能的考虑选用1张、2张、4张或8张,且在服务器内左右对称,如下图:
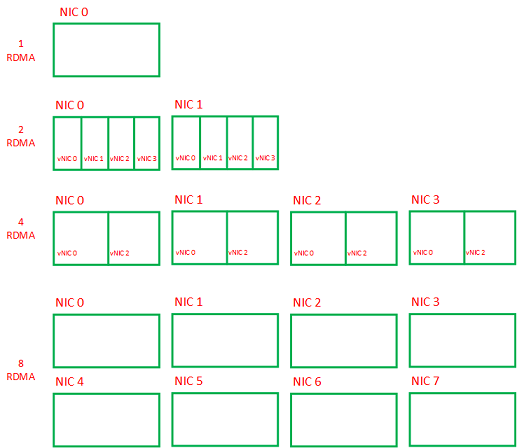
从成本与效率的角度考虑,每台服务器内的网卡可以是以下配置:
- 1张物理RDMA网卡,不进行虚拟化,直接用双工通道,适合选用2D/Hierarchical Ring拓扑算法;
- 2张物理RDMA网卡,可以每张虚拟化出4个虚拟网卡,2X4共8卡,适合选用2D-MESH、2D-Torus拓扑算法;
- 4张物理RDMA网卡,可每张虚拟化出2个虚拟网卡,4X2共8卡,适合选用2D-MESH、2D-Torus拓扑算法;
- 8张物理RDMA网卡,不需要虚拟化,直接采用双工通道,适合选用2D-MESH、2D-Torus拓扑算法;
在实际的分布式训练生产集群中,集合通信算法也可以结合RDMA网卡端口(包括虚拟化的)的具体个数进行设计,而拓扑算法的选择也是需要根据成本与效率的进行合理取舍的。
2.4 网络结构抽象
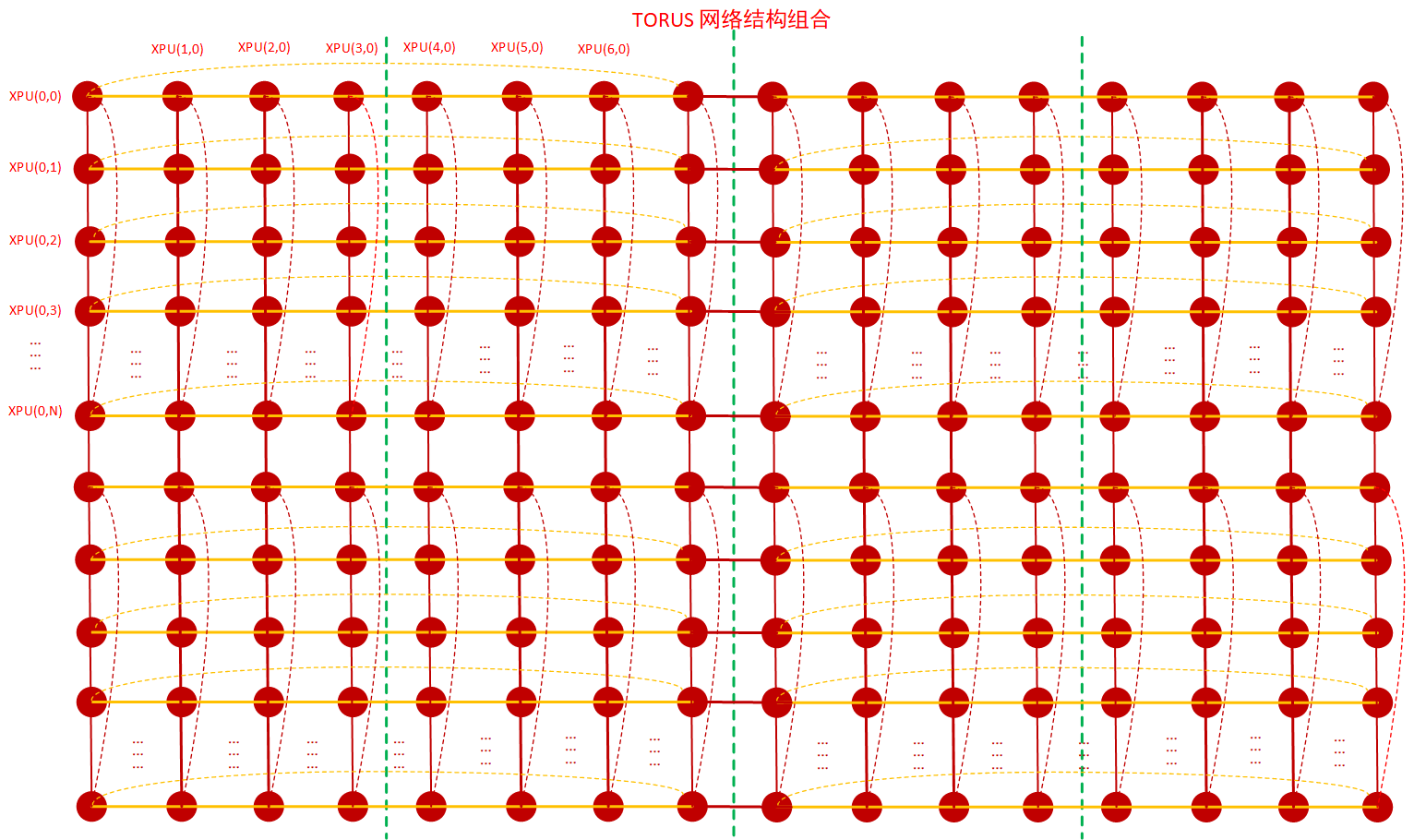
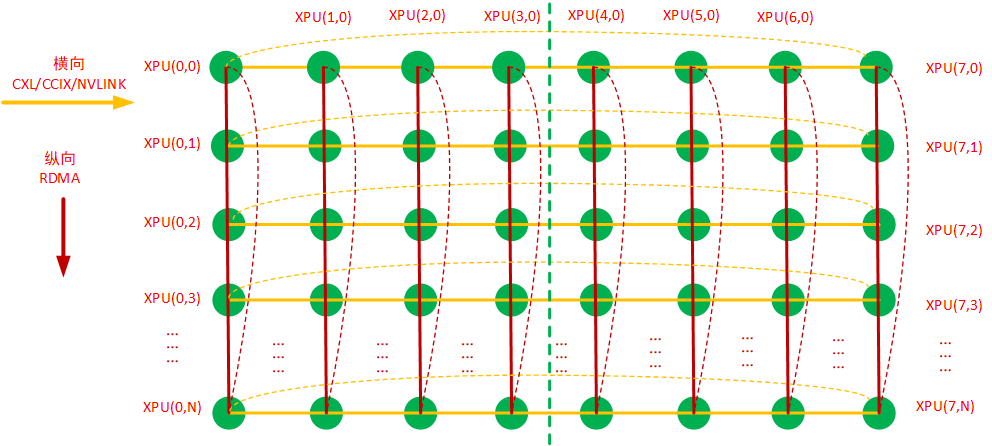
网络根据连接情况可分为ring结构、mesh结构、 torus 结构以及tree结构,基于以上的服务器内网络互联结构、服务器间网络互联结构以及网卡的具体情况,可以抽象出一个网络结构,即二维环面网络:Torus 网络,而Torus网络横向与纵向都可以看成ring结构,因此相应的拓扑算法基本上就是Ring-Based 集合通信拓扑算法。如下图:
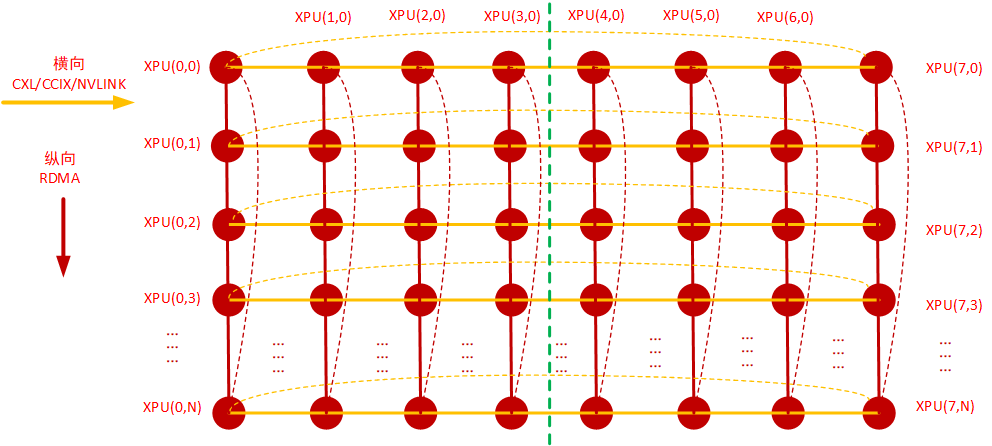
TORUS网络是常见的大规模并行计算机的互连网络,在上图这个Torus网络里:
1)横向:主机内8卡通过私有连接协议,比如CXL/CCIX/NVLINK等组成一个或多个ring,如上图的黄色连接线,横向8卡组成二维Torus的横向维度;
2)纵向:主机间通过RDMA(RoCE/IB)网卡、交换机互联组成1到8个ring,如上图的红色连接线,纵向采用RDMA网卡组成二维Torus的纵向维度;
3)根据物理网卡数量、网卡虚拟化以及PCIe Switch亲和性的实际情况:
- 每台服务器1张网卡可组成主机间一个ring,网卡与XPU0 挂载同一个PCIE switch上,依据最佳实践原则(比如性能、成本、客户要求等),适合选用2D/Hierarchical Ring拓扑算法;
- 两张网卡可组成主机间两个ring或者经过虚拟化组成8个ring,根据PCIE SWITCH亲和性原则,一张网卡与XPU0挂在同一个pcie switch,另一张网卡与XPU4挂在同一个pcie switch,依据最佳实践原则(比如性能、成本、客户要求等),适合选用2D-MESH、2D-Torus拓扑算法;
- 4张网卡、8张网卡以此类推,也是根据PCIE SWITCH亲和性原则进行连接,主机间RDMA物理网卡不够就虚拟化网口来凑,并且要服务器内的RDMA出口端口数左右平衡,依据最佳实践原则(比如性能、成本、客户要求等),也是适合选用2D-MESH、2D-Torus拓扑算法,这样才能发挥多张网卡以及XPU的算力优势。
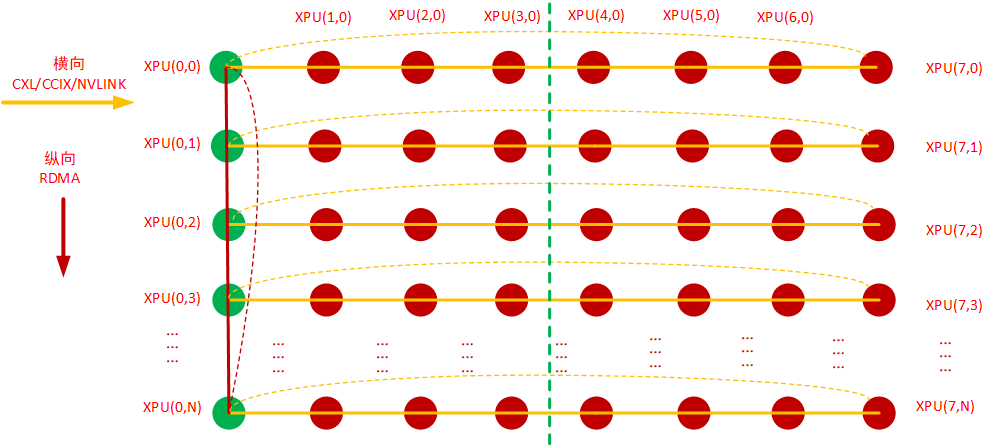
4)更复杂的Torus网络组合关系还可以如下图,从横向只有 主机内的8卡纵向只有主机间的RDMA互联,扩展到 横向与纵向 主机内互联与主机间互联混合,但本文仅限于在横向8卡的二维Torus网络下进行拓扑算法选择与设计,因此不展开讲述。
3. 常用的通信拓扑算法
Torus 网络结构可以解读本文中的物理网络互联结构的一切,而Torus网络的横向与纵向都可以看成ring结构,因此,相应的集合通信拓扑算法都可以看成是Ring-Based 集合通信拓扑算法。
3.1 Ring AllReduce
在分布式训练中,Ring 是最基础的互联结构,在本文中Ring AllReduce的应用场景是在服务器内将8张加速卡组环通信进行分布式训练。每个XPU都是这个主机内互联环上的一个计算节点,每个节点都有一个前向和一个后向,它只会向它的前向接收数据,并向它的右向发送数据,如下图所示,8张XPU 通过主机内的私有互联网络组成一个环,当然因为这些通信网络是双工的,这8张XPU训练加速卡也可以看成是通过多个逻辑环互联起来的,同时缺点是,如果这个ring太大,Ring Allreduce的效率也会变得很低。
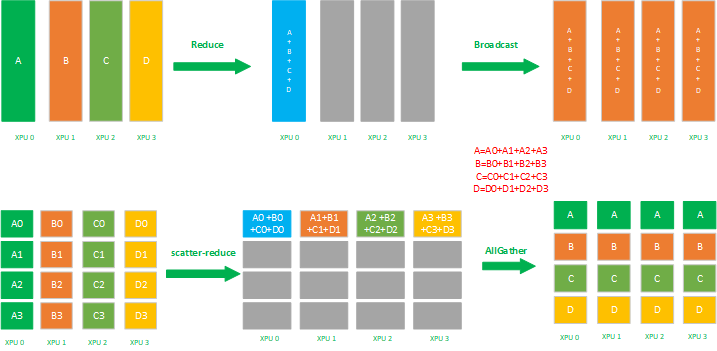
Ring Allreduce 有两种组合实现策略:1)先Reduce后broadcast;2)先ScatterReduce后AllGather,这两个策略执行后都会让每个XPU节点得到一样的平均梯度,如下图所示:
3.1.1 Reduce +broadcast
在Reduce + broadcast里,reduce先将8张卡的梯度reduce sum到master节点 XPU0 上,再通过broadcast将这个总的平均梯度复制给其他XPU,如下图:
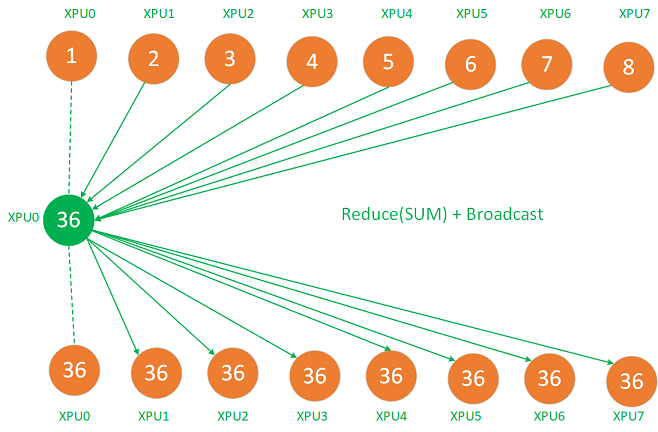
Reduce + broadcast这种策略有几个比较大的缺点:1)8张卡的数据都reduce sum到一张卡,假设每张卡的梯度是100MB,8张卡就是800MB,这可能存在XPU 0计算很久,而其他7张卡空闲的情况存在,整体效率不高;2)XPU0 的网络带宽可能会成为瓶颈,8张卡的数据都只能通过XPU0的互联网络进行reduce和broadcast,在数据量比较大的场景 XPU0的带宽成为瓶颈;3)8张XPU不都是两两全互联的,因此,要把8张卡的数据一次Reduce或broadcast,这一点受限于网络互联条件做不到,那么就需要采用 ring或tree的策略进行reduce或broadcast,这样效率也不高。
3.1.2 ScatterReduce + AllGather
Ring AllReduce 的Ring ScatterReduce + Ring AllGather策略组合里,每个 XPU只会从前向接受数据,并发送数据给后向,其算法主要分为:
- ScatterReduce:这一步会先scatter拆分数据块再进行reduce,并且在执行完毕后,每张XPU都会包括一个完整的经过融合的同维梯度;
- AllGather:这一步会进行全局Gather同步,最后所有 XPU都会得到完整的大的整个梯度;
Ring ScatterReduce + Ring AllGather是效率比较高的 Ring AllReduce 组合策略,这个策略考虑到了XPU上的梯度可能很大的情况,比如一个梯度有400MB,在scatterreduce阶段就会先被拆分成 ring上XPU个数份,比如主机内XPU个数等于8,那么 这400MB 就会被 拆分成8份,每份50MB,从而减少了加速卡的计算量以及节约带宽。此外,scatterReduce通过将数据拆分成小块,同时并发进行scatterReduce,从而将通信时间隐藏在计算时间内进而提高Ring AllReduce的效率。
3.1.2.1 ScatterReduce
首先, ScatterReduce先将梯度拆分为N个更小的块,N等于ring里XPU个数,8张卡就拆分成8份,然后进行N-1次scatterreduce迭代。在第一轮迭代中XPU 0上的A0传递给XPU1上A1并相加,XPU1上的B1传递给XPU2上的B2并相加,XPU 2上的C2传递给XPU3上C3并相加,XPU3上的D3传递给XPU4上的D4并相加,以此类推,过程如下图左侧:
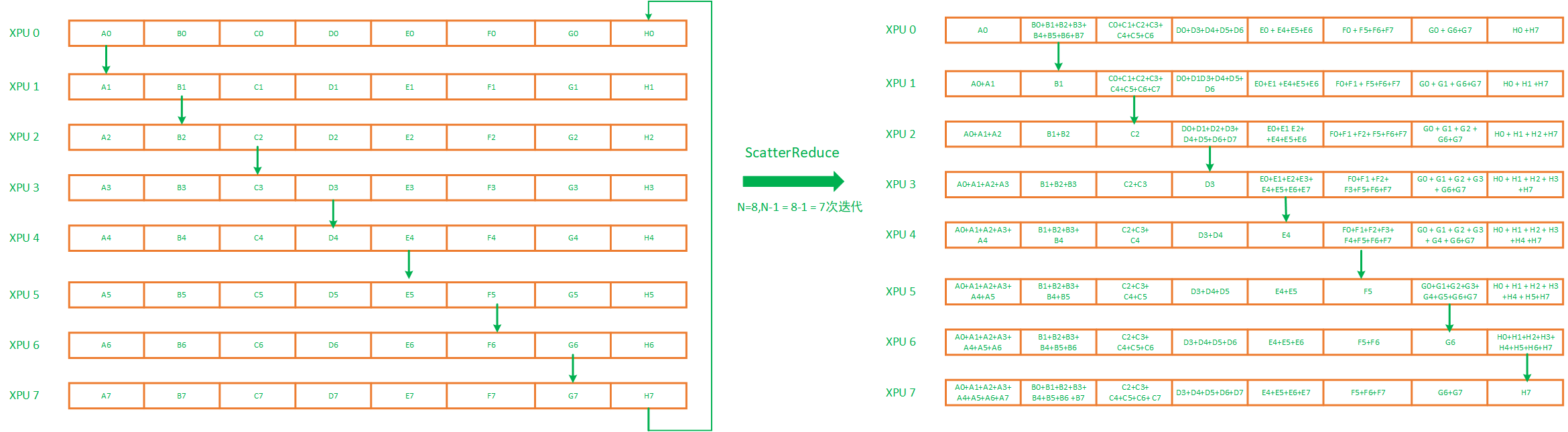
接下来,XPU还会进行N-2次 ScatterReduce 迭代,在每次迭代过程中,XPU都会从前向接收一个小梯度块并累加到自己的梯度块中,并且也会向其后向发送一个小梯度块,每个XPU接收和发送的小梯度块在每次迭代中都是不同的,这样经过迭代,到最后,每个XPU将有一个完整的同维梯度,该块梯度中包含所有XPU中该块对应的所有梯度的总和,如上图右侧的累加和部分。
3.1.2.2 Allgather
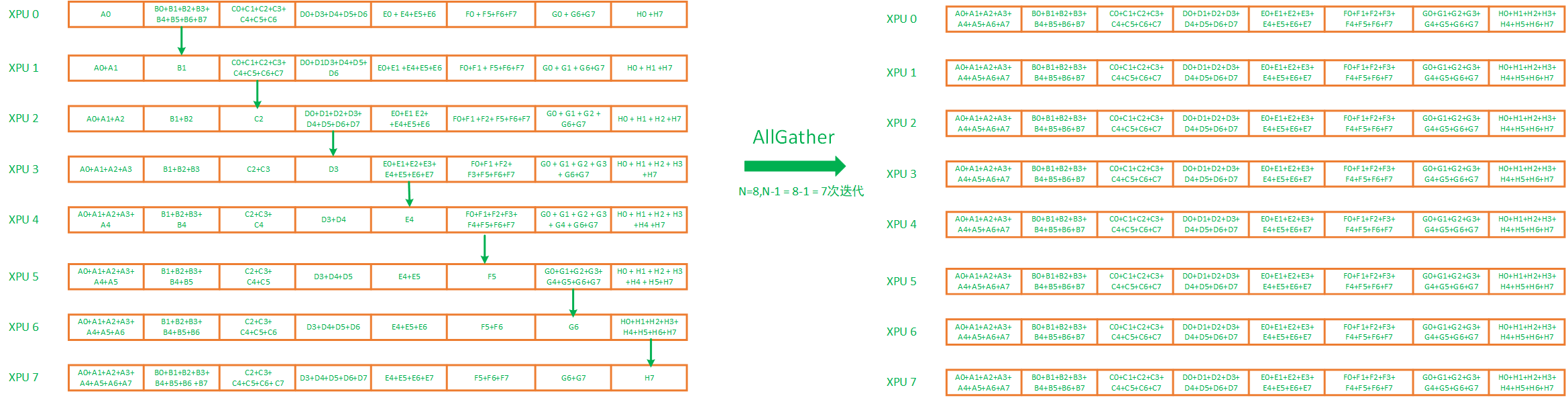
在scatterReduce迭代完成之后,每个XPU都会得到一个同维度的完整的梯度累加值,将这些完整的累加值复制到其他的加速卡后,才算完成allReduce。Allgather的迭代次数与scatterReduce是相同的,也都需要进行N-1次(N是ring上的XPU卡数)迭代,但是不同于ScatterReduce的是allGather没有reduce的过程,只有数值的复制。这样迭代到最后,每个XPU都得到大的拆分前的梯度的完整累加值,如下图演示了这一过程,从第一次迭代开始,到最后AllGather拿到整体的结果。这里头的具体过程就不在这里描述了,可以查相关资料。
Ring AllReduce 实现简单,在ring较少时,效率也较高,但是在ring比较大时需要的网络节点跳数变得比较大,通信时延增加,因此效率也会降低。比如,一个1000张XPU的 ring,这里头网络的跳数 是N-1= 1000-1 =999, 同时传输的过程中,传输效率还受效率最低、带宽最低的XPU的限制,这时网络上的时延会变得巨高,这个时候ring allreduce拓扑算法就变得不大适用这个场景,同时如果在异构网络里涉及网络的不同连接方式,Ring AllReduce也不大适合使用,因此就需要采用另外的更适合网络结构的更高效的集合通信拓扑算法来进行优化。
3.2 2D-Ring AllReduce
如果一台2.1里的服务器只配置了一张RDMA网卡,每台服务器通过RDMA交换机互联,这个集群的网络是异构的(如下图),那么Ring AllReduce拓扑算法就不适用了,这个时候,对于这个网络拓扑结构比较适合的是2D-Ring AllReduce也叫Hierarchical Ring AllReduce。
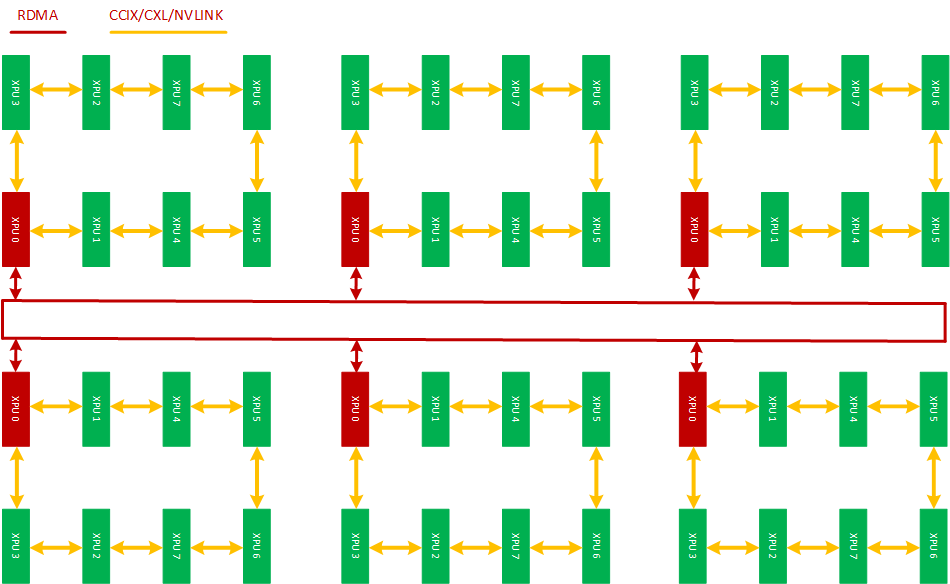
经过抽象,可以将这个网络结构表达成如下的Torus结构:
横向:每台服务器8个XPU节点,每个XPU节点通过私有协议网络互联;
纵向:每台服务器通过一张RDMA网卡NIC 0 通过交换机互联,这个网卡NIC0 与XPU0 挂在同一个PCIE switch上,满足具备亲和性条件,XPU0上的梯度可以通过NIC 0 与其他服务器上的XPU进行全局规约。
2D-Ring AllReduce的过程如下图所示:
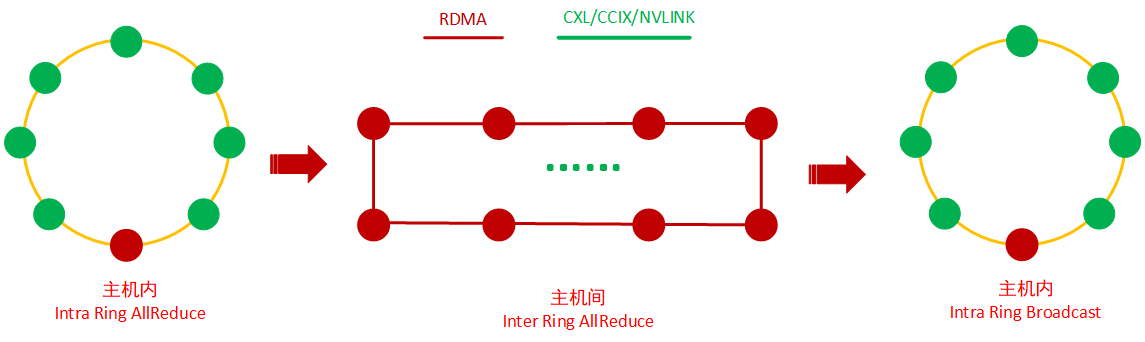
第1步,先进行主机内Ring AllReduce,也可以是 Ring Reduce或者根据主机内的互联情况选用的分层reduce方式,将8张卡上的梯度累加到Master节点 XPU0 上;
第2步,进行主机间XPU 0的 Ring AllReduce,将每台服务器的XPU0上的数据进行全局规约;
第3步,进行主机内Broadcast,将XPU0上的梯度复制到服务器内的其他XPU上
2D-Ring AllReduce能充分发挥异构网络的优势,将主机内、主机间的网络带宽充分利用起来。但是XPU的利用率也不是很高,比如在做主机间的Ring AllReduce,每台服务器内的其他7张XPU是处于空闲状态的。
再假设,如果每台服务器配置了 2张/4张/8张RDMA网卡,这个时候 2D-RING AllReduce又难以将网络的优势发挥出来,那么就需要选用 2D-Torus/2D-Mesh AllReduce拓扑算法。
3.3 2D-Torus AllReduce
考虑到服务器内PCIE SWITCH 的亲和性问题,2D-Torus至少需要配备2张 左右对称的RDMA网卡才能发挥这个拓扑算法的优势。在这个集群里主机内每张卡都通过私有的通信协议组成Ring,而主机间,可以通过RDMA网卡(包括虚拟化出来的)与RDMA交换机将XPU两两互联,这个网络也是异构的,如下图所示:
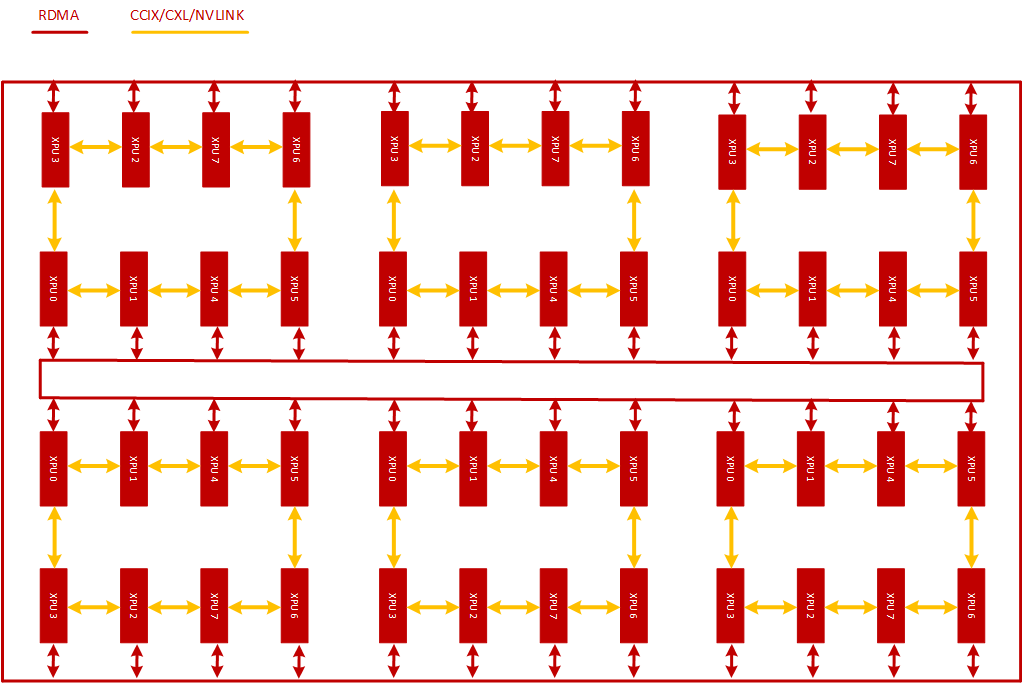
经过抽象,可以将这个网络结构表达成如下的Torus结构:
- 横向:每台服务器8个XPU节点,每个XPU节点通过私有协议网络互联;
- 纵向:每台服务器通过至少2张RDMA网卡NIC 0 /NIC 1通过交换机互联,这个网卡NIC0 与XPU0、1、2、3 挂在同一个PCIE switch上,具备亲和性条件,XPU0、1、2、3上的梯度数据可以通过NIC 0 与其他服务器上的XPU进行交换。网卡NIC1 与XPU4、5、6、7 挂在同一个PCIE switch上,具备亲和性条件,XPU4、5、6、7上的梯度数据可以通过NIC 1 与其他服务器上的XPU进行交换;
- 当然如果网卡是4个或者8个,也可以根据PCIE SWITCH的亲和性情况合理安排XPU与NIC的对应关系。
2D-Torus AllReduce的过程如下图所示:
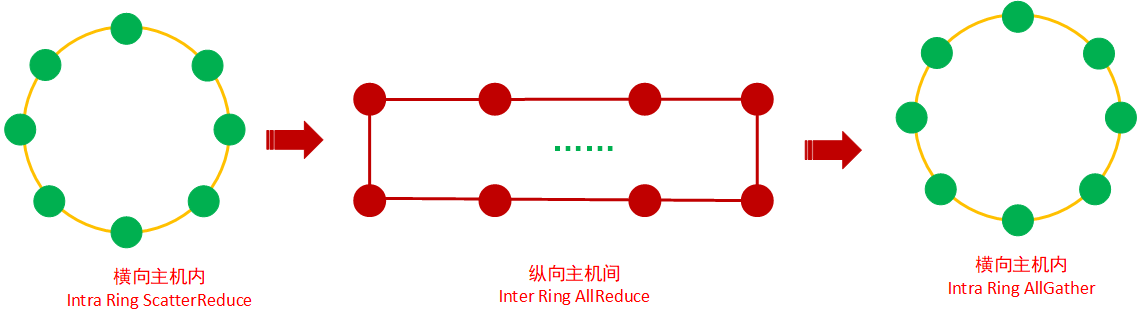
第1步,横向,先进行主机内Ring ScatterReduce,将主机内8张卡上的梯度进行拆分与规约,这样经过迭代,到最后每个XPU将有一个完整的同维梯度,该块梯度包含所有XPU中该块所对应的所有梯度的总和(参考3.1.2.1 scatterReduce)
第2步,纵向,进行主机间N个(N等于服务器内XPU个数,这里是8个)纵向的 Ring AllReduce,将每台服务器的XPU0-XPU7上的数据进行集群内纵向全局规约;
第3步,横向,进行主机内AllGather,将XPUi(i=0-7)上的梯度复制到服务器内的其他XPU上;
2D-Torus AllReduce能充分挖掘XPU的效率以及发挥异构网络里多网卡的优势,将XPU以及主机内、主机间的网络带宽优势充分利用起来。此外,除了 2D-Torus AllReduce外,2D-Mesh AllReduce也能发挥类似效率。
3.4 2D-Mesh AllReduce
2D-Mesh AllReduce的主要思想也是分层,与2D-Torus AllReduce类似,都是水平和垂直两个方向,但是有点差异,如下图所示:
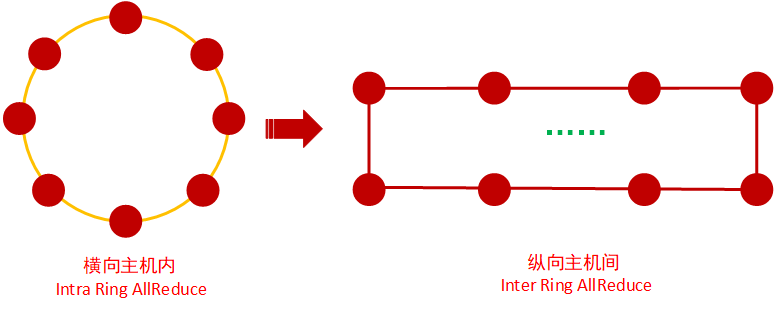
不同于2D-Torus AllReduce的拓扑算法,2D-Mesh AllReduce 过程是:
第1步,横向,先进行主机内Ring AllReduce 将主机内的8张XPU的梯度都进行规约;
第2步,纵向,进行主机间N个(N等于主机内XPU个数,这里是8个)纵向的 Ring AllReduce;
经过这两步,完成了整体的梯度累加,2D-Mesh AllReduce 也能充分发挥XPU与多网卡异构网络的优势,将XPU与主机内、主机间的网络带宽优势充分利用起来。这里的2D-Mesh与Google论文上的有点差异,主要是吸取了其分层的思想而不是复制其一样的设计。理论上2D-Mesh AllReduce对比 2D-Torus AllReduce,主机间AllReduce用的是 主机内8卡的全局梯度,数据量会比ScatterReduce部分来的大点,因此效率也会相应降低一点。
4. 问题探讨
如下图所示,基于Torus网络的结构,组合Ring AllReduce,2D-Ring AllReduce, 2D-Mesh AllReduce,2D-Torus AllReduce还能构建 3D-Ring/Mesh/Torus AllReduce拓扑算法,但是这些拓扑算法的效率需要进行实践才能证实,也许在规模较大的集群里才能发挥出3D 拓扑算法的优势。
关于 3D-Ring/Mesh/Torus AllReduce的拓扑算法,这里就不在阐述,可作为研究使用。
5. 小结
本文讲述了分布式训练里最常用的几个网络结构以及通信拓扑算法:
- Ring AllReduce 的最佳组合是 ScatterReduce + AllGather;
- 2D-Ring AllReduce = 主机内 ringAllReduce/Ring Reduce +主机间 RingAllReduce + 主机内Broadcast;
- 2D-Torus AllReduce = 主机内 Ring ReduceScatter + 主机间N个Ring AllReduce + 主机内Ring AllGather;
- 2D-Mesh AllReduce = 主机内Ring AllReduce + 主机间N个Ring AllReduce;
Ring AllReduce适合主机内互联Ring的情况使用,2D-Ring AllReduce适合一台服务器配置了一张网卡的异构网络场景,2D-Torus AllReduce与2D-Mesh AllReduce适合一台服务器配置了2/4/8张网卡的异构网络场景。
集合通信拓扑算法多种多样,但基于成本以及效率的取舍考虑,可生产适用的其实也不多,除了理论上的理解之外更重要的是自己编写代码去实践落地。除此之外,还需要解决网络带宽有限、网络容易出故障、落后者效应、部署约束、多租户等产品化的质量要求。日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
6. 作者简介
常平,中科大硕,某AI芯片公司深度学习高级软件主管、架构师,前EMC资深首席工程师,主要工作背景在深度学习、Ai平台、系统调优、大数据、云计算以及Linux内核领域。
7. 参考资料
[2] 《volta-architecture-whitepaper》
[3] 2D-HRA: Two-Dimensional Hierarchical Ring-based All-reduce Algorithm in Large-Scale Distributed Machine Learning
[4] Massively Distributed SGD: ImageNet/ResNet-50 Training in a Flash
[5] https://zhuanlan.zhihu.com/p/79030485 , 腾讯机智团队分享–AllReduce算法的前世今生
[6] https://zhuanlan.zhihu.com/p/370548366, ring allreduce和tree allreduce的具体区别是什么?
[7] https://zhuanlan.zhihu.com/p/184942777 , 分布式深度学习初探
[8] https://arxiv.org/abs/1811.06992 , Image Classification at Supercomputer Scale
8. 版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。