1. 概述
考虑到信息安全问题,这里不会写什么架构设计方案,更不会写什么具体的落地方案,有的只是从理论到实践再从实践回到理论的一些系统工程经验总结。超大规模集群性能调优的目标是为了解决以下两个系统级难题:
1)如何将Ai加速卡千卡分布式训练集群某个模型的加速比调到0.90+以上?
2)如何夯实Ai加速卡整体的分布式训练集群产品的系统级性能质量?
千卡级别的超大规模分布式训练集群性能调试是一个系统级的难题,将理论与实践相结合,从实践中来到实践中去,需要手把手的去调、去敲代码、系统梳理、具体问题具体分析、人技合一,才能有效达成目标。
系统级的性能优化考验的是具体问题具体分析的能力,考验的是根据不同的实际情况的变化进行全局优化的能力。
2. 基本约束条件
1)分布式训练必须以模型能收敛、精度达标、曲线拟合为前提,一切不能收敛、精度不达标、不能曲线集合的性能优化方案都是无效的;
2)加速比计算公式的 speedup = 分布式的单卡性能/单卡性能,这里的分母不是单机的性能,也不是单机内多卡并行计算的单卡性能,做低分母数值从而获得较高的加速比数据属于自欺欺人的行为;
3)理论上加速比也可以是 计算时间/(计算时间 + 非计算时间),因此,加速比调优的本质在于减少或者隐藏非计算时间;
4)这里讲的属于数据并行的分布式训练范畴,非模型并行、流水并行以及混合并行;
5)这里的Ai加速卡指的是某国产化加速卡,在软硬件功能与生态上对比GPU都还有很大差距,短板也更明显,因此更难以调试。
3.性能优化总诀
在软件工程中,不管场景是怎么样的,性能优化的策略本质上都可以抽象成以下几个方案:
少读少写少依赖: 少读,即减少读放大,减少需要读的数据量;少写,即减少写放大,减少需要写的数据量;少读少写的策略可以是提高cache命中率也可以是进行数据压缩,还可以是合适的读写算法与数据结构等,少依赖,高内聚低耦合、资源解耦与隔离,一个组件的IO尽量做到不需要等待另外组件IO完成才能返回;
时空换同异换: 时空换同异换讲的是性能优化的路数,解读开来说即是:时间换空间、空间换时间、同步换异步。例如:采用cache的功能可以减少计算的时间,这是存储空间换时间从而提升性能;采用批处理的方式提升性能,这是减少计算时间;采用同步换异步的方式提升性能也是减少计算时间;减少IO的数据量从而提升性能,这是存储空间换时间;缩短IO路径提升性能,这也是网络空间换时间,采用最新的硬件提升性能,这可以是计算换时间,也可以是存储或网络空间换时间;
硬件顺天性:硬件顺天性讲的是软件设计要遵循硬件的原生特性,XPU不同于GPU、CPU的亲合性、机械盘性能不如固态硬盘、磁盘数据分块需要对齐、内存性能好适合做缓存但是下电就丢数据、网络是不可靠的并且有带宽限制、RDMA网络比IP网络性能好、且是可以双工的,不同的应用场景要依据硬件的不同特性做架构选型以及架构设计等。
对于系统优化来说,不管场景怎么变化,不变的道理其实也还是上面那三项,性能优化也是万变不离其宗的。
4. 几个关键点
关于整体的超大规模分布式训练系统性能优化,需要考虑的主要关键点有以下几项:
工程方法论
极致系统平衡
具体问题具体分析
网络通信优化
数据IO优化
训练框架优化
模型优化
系统优化
下面将围绕这几项展开讲述。
5. 工程方法论之美
5.1 组织到位
千卡性能调优是个系统工程,要干活就首先需要有人,有人就需要组织能到位。这里的组织到位有两层意思:一是需要有人,需要组织给与人力保障以及多团队合作保障;二是合适的人,事是需要人去做的,攻坚的课题用到合适的人才具备达成目标的可能性,用错人半途而废或者数据造假忽悠群众、效果打折的可能性也不是没有。
5.2 架构先行
从系统而非单点的角度分析问题,要解决问题首先是需要能发现问题,在对调优任务进行拆解之前需要对性能调优方案先进行系统分析,挖掘出存在的软硬件问题拿出具体可执行的调优解决方案,并形成架构设计文档。
5.3 分而治之
系统思考分而治之,大问题拆解成小问题,将非常大的不确定性的千卡加速比 0.90+ 这个目标进行拆解,将非确定性的大问题拆解成确定性的小问题,步步迭代进行解决。宏观是不确定的,但微观却可以确定,系统梳理每个要素,拆解为确定的细分任务,先将确定的任务落实到人,再将剩下的不确定任务根据实际情况的变化,逐步进一步分解,逐步迭代。
5.4 小即是大
从主机内单卡到主机内多卡,新增主机内通信单元,从主机内多卡到主机间多卡新增主机间通信单元,这些系统间要素连接关系变化会引起系统整体功能的变化,因此,需要先聚焦主机内单机多卡调优,再聚焦主机间2机性能调优,在这二者达成既定目标后,后续扩展到千卡规模也就是水到渠成之事。
5.5 众策众智
众策众智多方协作,集群性能调优是个系统工程,需要多方合作与协调,其涉及多方组件,千卡性能调优是多方合作的结果,是软硬件联合,软件内部多方合作,跨部门跨团队联调达成的结果。
5.6 躬身入局
躬身入局不达目标不罢休,实践出真知,“黄沙百战穿金甲,不破楼兰终不还”,在认知上确定关键路径后,更重要的是躬身入局实践,一个问题一个问题的攻克,步步为营,步步迭代,一个小目标一个小目标的攻克递进。
6. 系统平衡之美
系统是有灵魂的,如下图《一根羽毛的力量》(图片来源于网络版权归原作者所有),其将平衡用到极致,风、呼吸、声音等微小的外部条件变化都可能造成失败,体现了整体的系统平衡之美。

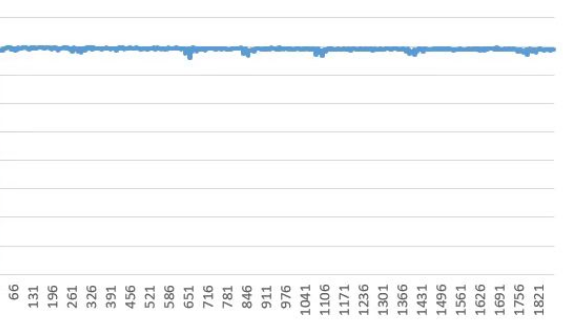
而分布式训练系统也有自己的灵魂,其可以表达为FPS每秒处理的帧数指标图,一个好的分布式训练系统FPS指标也是很有规律很漂亮的,如下图所示,千卡某模型加速比0.90+达标的训练集群FPS指标可以稳得如同一根直线,完美的诠释了什么是系统工程平衡之美。
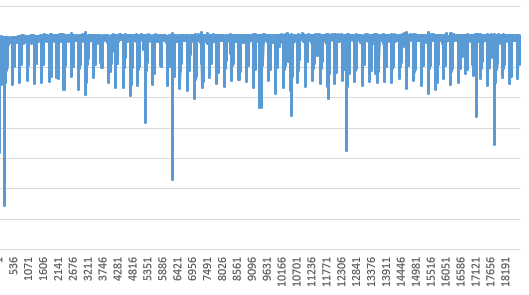
而一个加速比指标很差的训练系统FPS指标可能如下图,各种指标上串下跳极其不稳定,缺少一种平衡感。
7. 具体问题具体分析之美
GPU有适合GPU的最佳性能优化方案,XPU有XPU的最佳性能优化方案,而现有的分布式训练方案基本上都是基于GPU硬件体系结构以及CUDA的软件生态方案,不一定适合于各家国产化的AI加速卡的实际情况,因此针对国产化加速卡的性能优化方案也需要具体问题具体分析。
其实对于分布式训练性能优化来说,具体问题具体分析这一步才是最重要的,也是各路性能优化专家的掉坑点。每个AI加速卡都具备矛盾的普遍性也具备自身的矛盾特殊性。要根据自家加速卡的实际情况具体问题具体分析,首先是需要能发现具体的问题,再根据这个具体问题进行具体分析,再根据分析的结果给出最佳适合的性能优化方案,这就跟人的能力强相关,不是看完这篇文章或者网上找的几篇论文就可以完成超大规模训练集群性能优化这个系统级难题的。
各个国产化厂家的硬件存在矛盾特殊性,软件也存在自身的矛盾特殊性,具体问题具体分析就是挖掘这些矛盾特殊性,形成系统性的调研报告,从而给出系统级的性能优化方案。
8.网络通信优化之美
8.1 网络拓扑结构
实践证明,如果网络优化的足够到位,2D-RING ALLReduce拓扑算法就能满足千卡集群某模型的加速比达0.90+的,如下图,主机内一个ring Allreduce,主机间一个ring AllReduce,再主机内一个Broadcast:
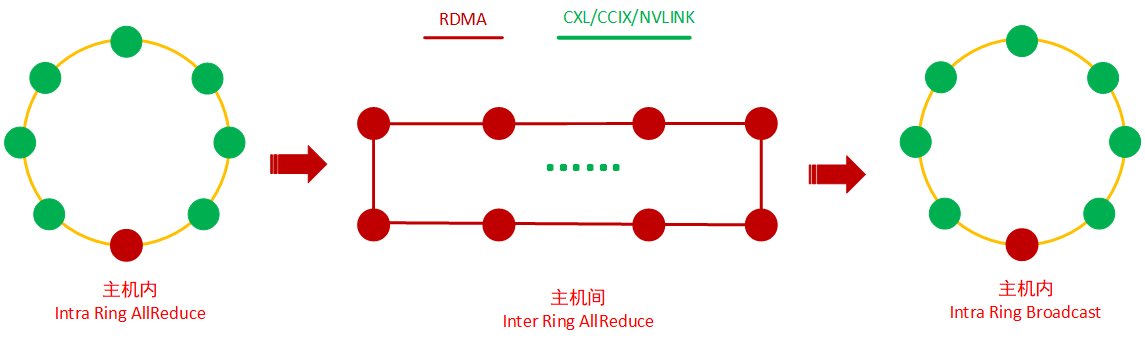
这种拓扑算法只需要消耗一个RDMA网卡的一个网口以及一个交换机端口,因此,适合在有成本约束的生产环境,除非有更高的加速比要求,不然简单的两层RING结构拓扑算法就能满足绝大多数的生产需求。
而这种网络拓扑优化的关键在于主机内从单卡到多卡,发生了物理连接结构变化,主机间从单机到多机也发生了物理连接结构的变化,要专注于这两种结构变化的优化,使得FPS性能掉的足够少,才有望在千卡这种规模的集群下获得较高的加速比。
8.2 网络存在的问题
网络是分布式训练系统的连接方式,因此分布式训练系统也继承了网络的原生缺点,即:
- 网络是不可靠的;
- 网络是会出故障的;
- 网络是有时延的;
- 网络是会抖动的;
- 网络是不安全的;
- 网络是会丢包的;
- 网络是有带宽限制的;
- 网络消息是会乱序的
这些原生缺点的存在会给分布式训练系统带来以下一些问题:
8.2.1 同步通信问题
在Ring拓扑下每个XPU只与相邻XPU通信,而在该拓扑下所有传输都是在离散迭代中同步进行的并且每张XPU都需要进行迭代周期同步,所有传输的速度受到环中相邻XPU之间最慢(或最低带宽)连接的限制,性能瓶颈也非常明显。
8.2.2 落后者问题
落后者 (Straggler)问题,指的是当一个平台上不同的工作单元具有不同的运行性能时,整个系统的性能受限于运行效率最低的工作单元。Straggler可能是确定性的,比如某台机器的计算能力或者网络带宽低于其他机器。也可能是随机性的,比如低性能是因为资源共享,后台操作系统任务,缓存,功耗限制等引起的,解决Straggler问题的一种常用方式是进行异步训练。
8.2.3 异质问题
当前我们的国产化软硬件存在一些技术约束,这些约束条件会造成很大的计算异质问题,比如主机内网络非全连接,主机间RDMA全连接并且主机间RDMA有些场景下又是分层交换机互联,这就是网络异质,而目前使用的Ring-Based通信拓扑又是同步的,当整个集群内存在较慢的计算节点时,整个系统的性能受限于这个性能最差的节点。除了网络拓扑,网络本身的缺点也决定了需要对网络进行细致的优化。
9.数据IO优化之美
在分布式训练系统里,数据IO最重要的优化即数据预取以及IO时间隐藏的优化,如下图所示,数据首先从磁盘读取进主机缓存,再从主机缓存读取进加速卡内存HBM,这个过程带宽是受PCIE限制的,如果IO 速率跟不上加速卡的计算消耗数据速率,数据IO就会成为整个训练系统的瓶颈。
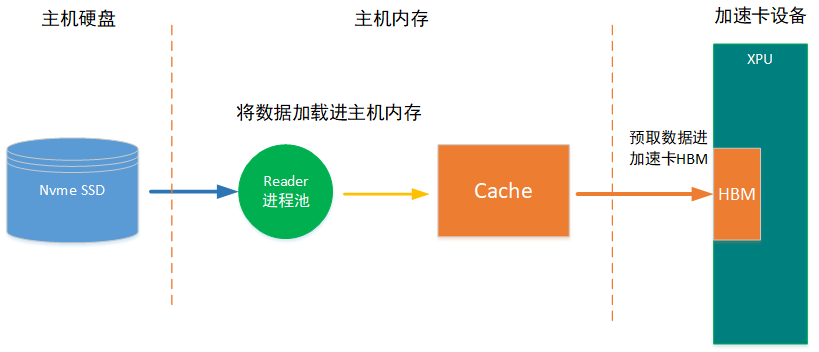
基于此,需要打通pinned memory ,数据预取以及IO时间隐藏功能。
10.训练框架优化之美
如下图所示,神经网路是分层的,因此训练框架计算出来的梯度也是分层结构,如果不进行融合优化,那么每个梯度层都会触发一次全局通信规约,100个梯度就需要进行100次全局通信100次全局规约,这种行为会极大的拖垮整个分布式训练系统的性能。
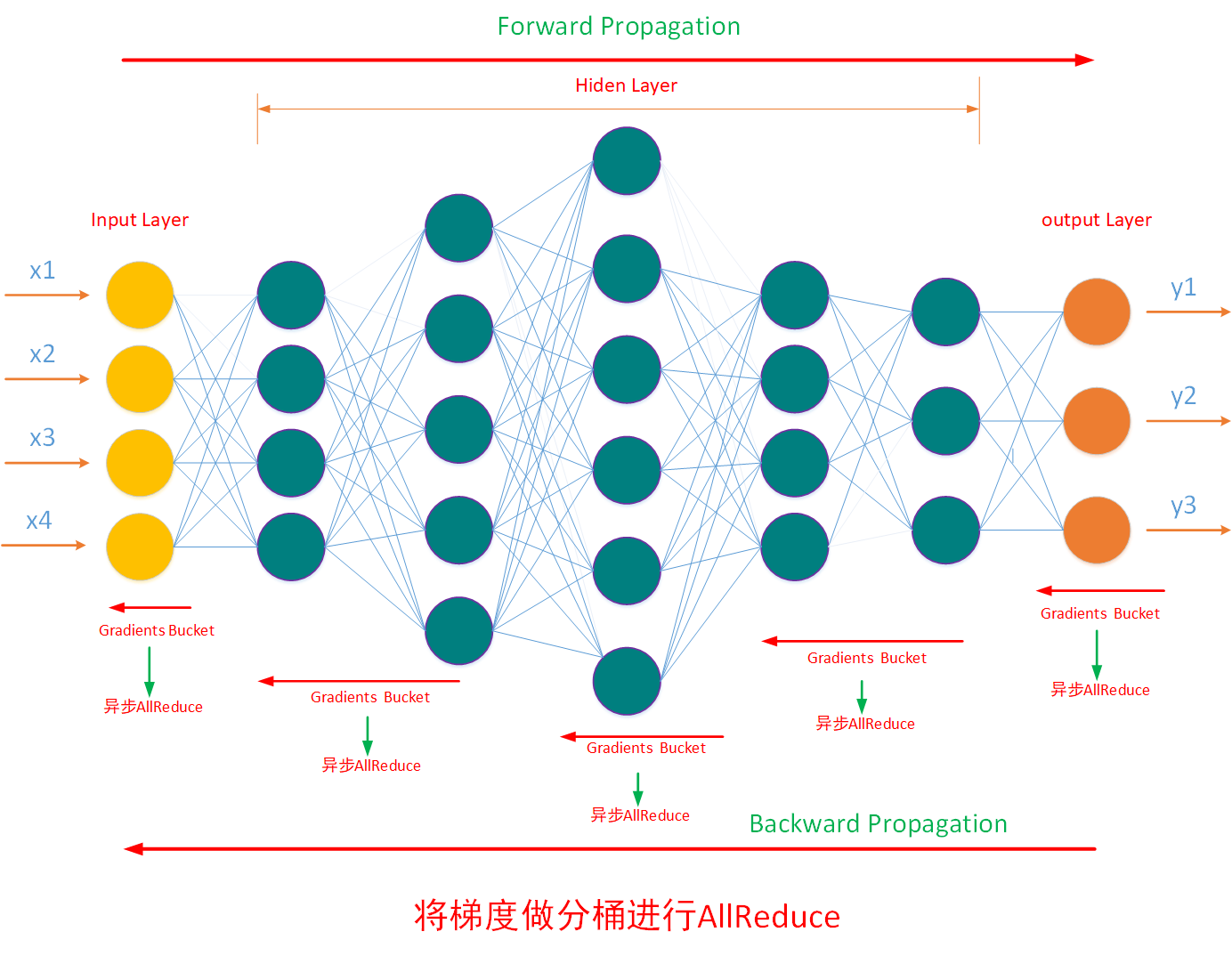
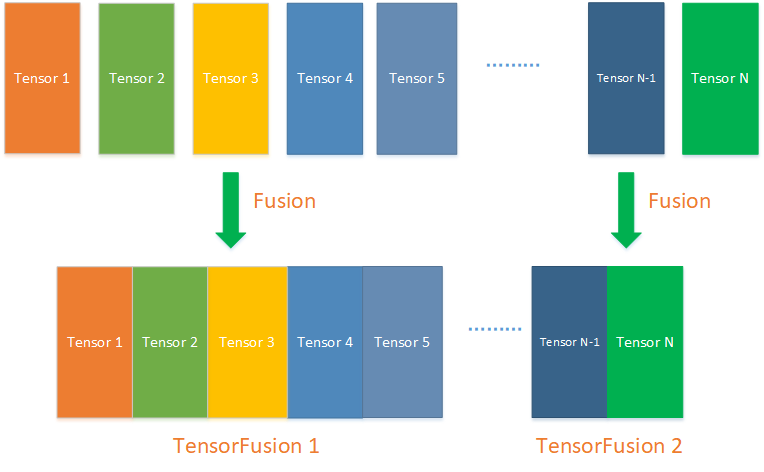
基于此需要采用 梯度融合的策略进行优化,通过梯度融合计算将多个梯度合成一个,从而减少全局规约的次数能大幅提高分布式训练的训练性能,如下图所示,将N个小梯度Tensor合成两个,能将全局通信的次数减少到2次,从而大幅提升训练性能:
11. 模型优化之美
这需要具体问题具体分析,根据不同的模型以及实际情况进行优化。除了通信、框架、数据IO等,模型也是影响整体系统性能的一个关键点,数据dataset的效率,训练session 的合并还是分离,采用的是动态训练策略还是静态训练策略,FPS统计的计算方式这些要素也会极大的影响整体的系统性能,因此也需要针对具体情况进行具体分析。
12.系统优化之美
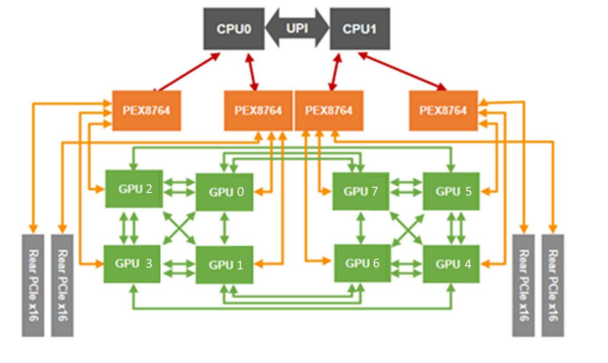
如下图,是一个AI服务器主板,在这个服务器里,加速卡间的通信带宽大于PCIE带宽又大于CPU间的UPI带宽,因此需要启用NUMA优化,使得数据不跨越UPI通信,另外CPU 的AFFINITY也需要进行平衡优化。
除了CPU的优化,计算机节点还有一下特性:
- 计算机节点是会出故障的,主板、CPU、网卡、硬盘、内存、电源等都会出故障,比如老化、失效等;
- 计算机节点内的操作系统是会突然奔溃不能提供服务的;
- 计算机节点是会突然掉电的;
- 计算机节点里的内存下电是不保数据的;
- 计算机节点的资源是有限的:CPU是有算力上限的、内存是有大小限制的、网卡有吞吐量限制、硬盘有空间大小限制以及速率限制;
这些特性也会影响到训练FPS的平衡,也需要针对性的根据具体情况进行优化。
13. 小结
本文介绍了从实践中来的关于一些超大规模训练集群性能优化的理论上的思考,考虑到信息安全问题,有些地方写的不是很透明,见谅。另外性能优化也是需要具体问题具体分析,根据不同的实际情况而进行优化的,普遍的策略可以学习,但是特殊的情况考验的还是个人以及团队发现问题、分析问题、解决问题的能力。
日拱一卒,功不唐捐,分享是最好的学习,与其跟随不如创新,希望这个知识点对大家有用。另作者能力与认知都有限,”我讲的,可能都是错的“,欢迎大家拍砖留念。
14. 作者简介
常平,中科大硕,某AI芯片公司深度学习高级软件主管、架构师,前EMC资深首席工程师,主要工作背景在深度学习、Ai平台、系统调优、大数据、云计算以及Linux内核领域。
15. 参考资料
[2] NF5468M5 用户手册
16. 版权申明
本文的版权协议为 CC-BY-NC-ND license:https://creativecommons.org/licenses/by-nc-nd/3.0/deed.zh
在遵循署名、非商业使用(以获利为准)以及禁止演绎的前提下可以自由阅读、分享、转发、复制、分发等。